マルチユーザ機械学習環境をJupyterHubとKubernetesで構築
最近お手伝いしている会社で、機械学習・デープラーニングを学ぶユーザ向けに、ユーザごとのJupyter Notebookをウェブサイト上で操作できるようにした仕組みを構築しました。どのような課題があってどのように構築したのかを説明したいと思います。
Jupyter Notebookは以下のようにウェブブラウザ上でコードを実行してその結果を保存し共有できます。再度実行も簡単にできるので、機械学習・ディープラーニングの実行コードを共有するのに便利です。
 (
(その会社は機械学習のEラーニングを社会人向けに展開しており、ユーザはウェブページにアクセスして学びます。内容的にはPython、機械学習、ディープラーニングだったりするのですがモデルの学習のため、コーディング(いわゆる写経)自体は、ユーザがもっているPCのローカル環境上にJupyter Notebookを構築してもらい実行していました。その他にJupyter Notebookで実行・提出が必要な演習課題があるのですが、それは生徒がローカルで実行しその結果を生徒から採点者にメール送信し、採点してからユーザに返信しています。
ウェブ上でコンテンツを確認できるところまではいいのですが以下のような課題がありました。
- 生徒の環境構築が面倒: 現状のシステムだと環境を生徒が構築しなければいけません。
Pythonをインストールするだけならまだしも、機械学習のパッケージを入れないといけないためインストールが手間で時間がかかります。また機械学習は日進月歩で進化がはやいため特定のバージョンの組み合わせでないと動かないなどの問題があります。生徒のOSの種類やOSバージョンも異なるためでインストールで躓いたときの対応が困難でコストがかかります。 - 提出が必要な演習課題の管理が煩雑: 生徒が提出した演習課題の管理が非常に煩雑です。生徒からメールで提出されるため運営側が生徒ごとにまたバージョンごとに管理しなければいけません。採点済みなのか再提出が必要かなど管理することが大変です。小さいスケールのうちはいいですが、大人数の生徒がいる場合、破綻するのは目に見えています。
今回、JupyterHubをKubernetes上で構築することにより以下のメリットが得られるシステムを構築しました。
- ウェブページにアクセスするだけで自動的に各生徒専用の
Jupyter Notebookが立ち上がります。学習に必要なTensorFlowなどのPythonパッケージがバージョン固定ですでにインストールされています。 - 生徒がウェブページ上で演習課題が実行し提出できます。運営側も提出された課題を管理画面のウェブページ上で確認できるので個別にファイル管理する必要がありません。
Kubernetesで構築してあるため生徒が増えても自動でスケールできます。
それではJupyterHubをどのように構築しているか説明します。
構成
システムはJupyterHubをKubernets上で構築できるzero-to-jupyterhub-k8sをカスタマイズして使用しています。
構成ですが以下のようになっています。
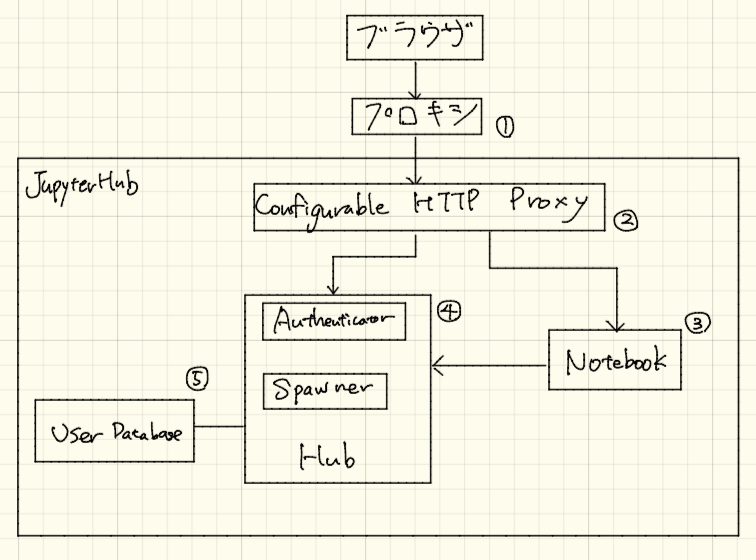
JupyterHubで囲われているところがJupyterHubを使って構築した部分で、①のProxyはコンテンツ圧縮で必要だったため追加しています。実際にはJupyter Notebookはiframeをウェブページに埋め込んであるので運営側のシステムもこの図の外側にあるのですが、簡単のためJupyter Hub関連のみ表示してあります。
基本的に、Technical Overviewで説明してあるとおりなのですが、順に説明します。
- ①は、③のNotebookのコンテンツをgzipで圧縮してクライアントで返すための
nginxのサーバです。WebSocketを通す必要があるのでその設定もしてあります。 - ②はconfigurable-http-proxyは
JupyterHubへのアクセスの入り口となるプロキシです。後述するHubやNotebookへリクエストを割り振ります。configurable-http-proxyはREST APIでルーティングを設定することができます。Hubがユーザ認証をしてルートを設定しています。ルートを保存する先はデフォルトではメモリです。 - ③は
Notebook(Single-User Notebook Server)です。Jupyter Notebookが実装されており、ユーザごとに用意されます。 - ④は
Hubでユーザ認証のためのAuthenticatorや、ユーザがアクセスしてきたときに、そのユーザ専用のPodを用意するSpawnerが動作しています。ユーザが認証されるとブラウザにクッキーが保存されるのでリクエストごとにデータベースにユーザをチェックする必要はありません。 - ⑤はユーザデータベースですが、
JupyterHub用のデータベースと、ウェブ用のユーザが格納してあるデータベースがあります。JupyterHubはデータベースはデフォルトではSQLiteですが、障害にそなえPostgreSQLにしてあります。
上記は基本的なJupyterHubのシステムですが各種以下のようにカスタマイズしています。
Hubのカスタマイズ
Hubはユーザ認証の部分を変更しています。JupyterHubはOAuthなど各種Authenticatorsがあるのですが、どれも今回の用途には適用できなかったので簡単なコードを書いてカスタマイズしたAuthenticatorを使っています。
ブラウザがJupyterHubにアクセスした際にログインなしでユーザごとのJupyter Notebookを立ち上げたかったので、クライアントがトークンを送る形式にしてそのトークンを使って、Authenticatorがデータベースに問い合わせてユーザ情報を取得し、Jupyter Notebookを立ち上げる形式にしました。そうすればトークンがクッキーにあるだけで認証できログイン画面が必要ありません。
Jupyter Notebookのカスタマイズ
Jupyter Notebookもカスタマイズしていて各種Pythonパッケージのバージョンを固定したり権限を絞ったりしています。特にJupyter NotebookはKubernets上にPodで立っているのでユーザが自由に操作できるサーバがクラスター内にあり非常に危険です。ネットワークの制限やサーバ自体の権限を厳しく設定してあります。
まとめ
JupyterHubを使うことでJupyter Notebookをスケール可能な形でユーザに提供できるようになりました。その他にも以下のような事もしています。
- 一定時間アクセスされていない
Jupyter Notebookは自動的にPodから削除しています。 - ユーザに提供するコンテンツを
git管理していて更新されると自動的にユーザに提供しているコンテンツも更新されます。 JupyterHubでは管理者を設定でき、管理者は他のユーザのJupyter Notebookにアクセスできます。管理者かどうかもユーザデータベースを参照して自動的に更新しています。Jupyter Notebookの使えるCPUやメモリのリソース制限をしています。
ユーザに不便なく安全に使ってもらえるためにはいろいろカスタマイズする必要がありますが、同じ環境のJupyter Notebookがすべてのユーザに提供できるのはメリットが非常に大きいので、そのような課題で困っている場合は1つの選択肢となるかなと思います。特に以下の人には役立ちそうです。
- 大学などで生徒にJupyter notebookを使用して課題を提出している先生
- Eラーニングでユーザに機械学習・ディープラーニングの環境をオンラインで提供したい企業
何かあれば手伝えることがあるかもしれませんのでご相談があればTwitterなどでおまちしております。