ECSで運用しているサービスにEKSを導入し移行する - 運用編
前々回のEKS構築、前回のECSからEKSへ移行でEKSでのサービスの構築は終わったのあで、構築したEKSの運用で役立つ情報を紹介したいと思います。
Kubernetesダッシュボードの利用
GKEではKubernetesダッシュボード相当のものがGKEのWebコンソール上でみれるので特に必要ないのですが、EKSはWebコンソール上からではノードやポッドの状態がぜんぜんわからないのでKubernetesダッシュボードを導入するといいと思います。
Tutorial: Deploy the Kubernetes Web UI (Dashboard)にどのようにすればダッシュボードがEKSで利用できるか手順があります。この通りにするとダッシュボードがデプロイされブラウザで確認することができます。
ダッシュボードにアクセスすると以下のようなページがみれます。
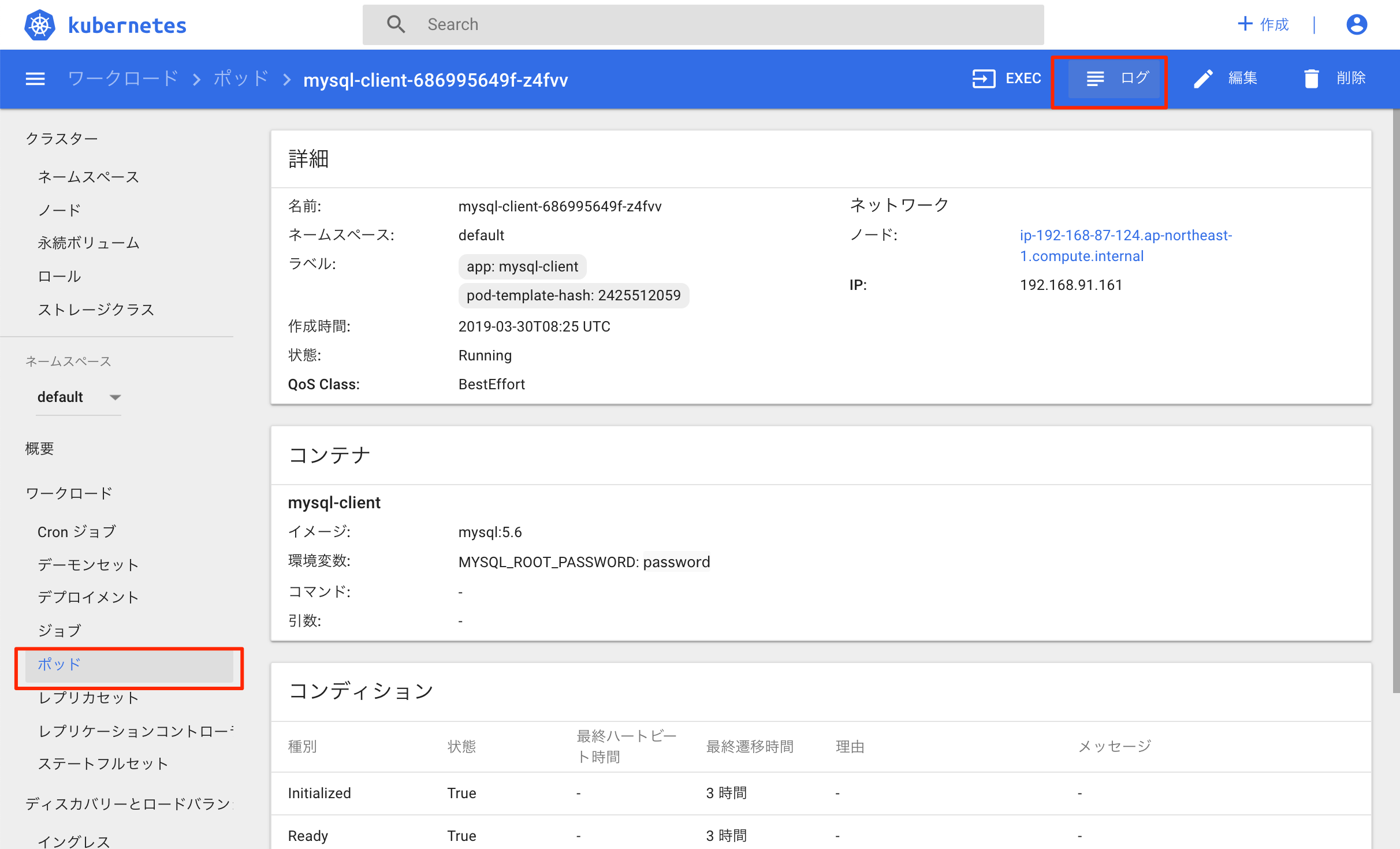
よく使うのはポッドを選んでから、右上のログを押すとポッドが出力しているログを見ることができるのでデバッグに役立ちます。さらにその左にあるEXECボタンを使うとポッドのシェルに入ってデバッグすることができます。kubectlコマンドでもできますが、クリックするだけで手軽にデバッグできるので便利です。
他のユーザもkubectlが使えるようにする
今回の記事のように設定しただけだと、他のチームメンバーがkubectlコマンドをインストールし実行しても、権限がないためEKSクラスタにアクセスすることはできません。権限を追加するにはManaging Users or IAM Roles for your Clusterを参照すればできます。ただこれだといちいちIAMユーザを追加しなければならず大変なのでグループにユーザを追加するなど他のやり方を探したのですが見つかりませんでした。
kubectlでよく使うコマンド
kubectl get podでまずポッドの確認ができます。-o wideオプションでどのノードで動いているかも確認できます。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-client-686995649f-z4fvv 1/1 Running 0 3h
kubectl logsはポッドの出力ログを見るときに使います。基本的にコンテナが起動したあとのログの確認のために使います。-fオプションでtail -fみたいにして出力を待つことができます。
kubectl logs mysql-client-686995649f-z4fvv
kubectl execはコンテナに接続してデバッグできます。
kubectl exec -it mysql-client-686995649f-z4fvv sh
kubectl deleteでポッドを削除できます。Deploymentが定義されている場合は自動でポッドが復旧します。ときどき調子の悪いポッドがあったときに削除して再起動すると治ることがある場合はこのコマンドで削除してやるといいです。
kubectl delete pod mysql-client-686995649f-z4fvv
Kubernetes内部からしかアクセスできないサービスもkubectl port-forwardを使えばアクセスできます。例えば以下を実行すればローカルの3306ポートにアクセスするとポッドの3306ポートにポートフォーワードされMySQLがデバッグできます。
kubectl port-forward mysql-client-686995649f-z4fvv 3306:3306
Helmを使う
HelmはKubernetesのパッケージマネージャです。例えばKubernetes上でMySQLを動かしたいと思ったときに、Helmを利用しないと自分でServiceやDeploymentのYAMLを書いてkubectlでデプロイしなければならず非常に手間です。Helmを使うとチャートとよばれるあらかじめ設定されたYAMLをhelmコマンドでインストールできその結果簡単にMySQLがKubernetes上で動かすことができます。実際のMySQLのチャートや、他のチャートを見てみるとイメージがつくかもしれません。
Helmのインストール
Amazon EKS Workshop > Helmを参考にすればいいかなと思います。
以下のファイルをkubectl apply -f helm-rbac.yamlで適用します。
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
Tillerをインストールします。
helm init --service-account tiller
インストールの確認をします。以下のようにClientもServerもバージョンがでれば完了です。
$ helm version
Client: &version.Version{SemVer:"v2.12.3", GitCommit:"eecf22f77df5f65c823aacd2dbd30ae6c65f186e", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.12.3", GitCommit:"eecf22f77df5f65c823aacd2dbd30ae6c65f186e", GitTreeState:"clean"}
CloudWatch Logsでポッドの標準出力・標準エラー出力を集約する
サービスを運用しているとエラーがおきたときにデバッグのためサーバの出力がみたいときがありますが、Fluentdを使えばCloudWatch Logsにログを集約することができます。
今回はFluentd CloudWatchのHelmチャートを使います。
こちらのHelmレポジトリはkube2iamを使って権限制御できるのでFluentd用のkube2iam設定をします。あたらしいk8s-fluentdというロールをAWSコンソールから作ってCloudWatchFullAccessのポリシーをアタッチして作成します。前回の記事でやったようにロールの信頼関係もワーカーノードのものを設定しておきます。
Helm用の設定ファイルを以下のように作成します。
image:
tag: v1.3-debian-cloudwatch-1
awsRegion: ap-northeast-1
rbac:
create: true
awsRole: arn:aws:iam::xxx:role/k8s-fluentd
extraVars:
- "{ name: FLUENT_UID, value: '0' }"
fluentdConfig: |
<match **>
@type cloudwatch_logs
@id out_cloudwatch_logs
log_group_name "#{ENV['LOG_GROUP_NAME']}"
auto_create_stream true
use_tag_as_stream true
</match>
<match fluent.**>
@type null
</match>
<source>
@type tail
@id in_tail_container_logs
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
read_from_head true
format json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</source>
<source>
@type tail
@id in_tail_minion
path /var/log/salt/minion
pos_file /var/log/fluentd-salt.pos
tag salt
format /^(?<time>[^ ]* [^ ,]*)[^\[]*\[[^\]]*\]\[(?<severity>[^ \]]*) *\] (?<message>.*)$/
time_format %Y-%m-%d %H:%M:%S
</source>
<source>
@type tail
@id in_tail_startupscript
path /var/log/startupscript.log
pos_file /var/log/fluentd-startupscript.log.pos
tag startupscript
format syslog
</source>
<source>
@type tail
@id in_tail_docker
path /var/log/docker.log
pos_file /var/log/fluentd-docker.log.pos
tag docker
format /^time="(?<time>[^)]*)" level=(?<severity>[^ ]*) msg="(?<message>[^"]*)"( err="(?<error>[^"]*)")?( statusCode=($<status_code>\d+))?/
</source>
<source>
@type tail
@id in_tail_etcd
path /var/log/etcd.log
pos_file /var/log/fluentd-etcd.log.pos
tag etcd
format none
</source>
<source>
@type tail
@id in_tail_kubelet
multiline_flush_interval 5s
path /var/log/kubelet.log
pos_file /var/log/fluentd-kubelet.log.pos
tag kubelet
format kubernetes
</source>
<source>
@type tail
@id in_tail_kube_proxy
multiline_flush_interval 5s
path /var/log/kube-proxy.log
pos_file /var/log/fluentd-kube-proxy.log.pos
tag kube-proxy
format kubernetes
</source>
<source>
@type tail
@id in_tail_kube_apiserver
multiline_flush_interval 5s
path /var/log/kube-apiserver.log
pos_file /var/log/fluentd-kube-apiserver.log.pos
tag kube-apiserver
format kubernetes
</source>
<source>
@type tail
@id in_tail_kube_controller_manager
multiline_flush_interval 5s
path /var/log/kube-controller-manager.log
pos_file /var/log/fluentd-kube-controller-manager.log.pos
tag kube-controller-manager
format kubernetes
</source>
<source>
@type tail
@id in_tail_kube_scheduler
multiline_flush_interval 5s
path /var/log/kube-scheduler.log
pos_file /var/log/fluentd-kube-scheduler.log.pos
tag kube-scheduler
format kubernetes
</source>
<source>
@type tail
@id in_tail_rescheduler
multiline_flush_interval 5s
path /var/log/rescheduler.log
pos_file /var/log/fluentd-rescheduler.log.pos
tag rescheduler
format kubernetes
</source>
<source>
@type tail
@id in_tail_glbc
multiline_flush_interval 5s
path /var/log/glbc.log
pos_file /var/log/fluentd-glbc.log.pos
tag glbc
format kubernetes
</source>
<source>
@type tail
@id in_tail_cluster_autoscaler
multiline_flush_interval 5s
path /var/log/cluster-autoscaler.log
pos_file /var/log/fluentd-cluster-autoscaler.log.pos
tag cluster-autoscaler
format kubernetes
</source>
# Example:
# 2017-02-09T00:15:57.992775796Z AUDIT: id="90c73c7c-97d6-4b65-9461-f94606ff825f" ip="104.132.1.72" method="GET" user="kubecfg" as="<self>" asgroups="<lookup>" namespace="default" uri="/api/v1/namespaces/default/pods"
# 2017-02-09T00:15:57.993528822Z AUDIT: id="90c73c7c-97d6-4b65-9461-f94606ff825f" response="200"
<source>
@type tail
@id in_tail_kube_apiserver_audit
multiline_flush_interval 5s
path /var/log/kubernetes/kube-apiserver-audit.log
pos_file /var/log/kube-apiserver-audit.log.pos
tag kube-apiserver-audit
format multiline
format_firstline /^\S+\s+AUDIT:/
# Fields must be explicitly captured by name to be parsed into the record.
# Fields may not always be present, and order may change, so this just looks
# for a list of key="\"quoted\" value" pairs separated by spaces.
# Unknown fields are ignored.
# Note: We can't separate query/response lines as format1/format2 because
# they don't always come one after the other for a given query.
format1 /^(?<time>\S+) AUDIT:(?: (?:id="(?<id>(?:[^"\\]|\\.)*)"|ip="(?<ip>(?:[^"\\]|\\.)*)"|method="(?<method>(?:[^"\\]|\\.)*)"|user="(?<user>(?:[^"\\]|\\.)*)"|groups="(?<groups>(?:[^"\\]|\\.)*)"|as="(?<as>(?:[^"\\]|\\.)*)"|asgroups="(?<asgroups>(?:[^"\\]|\\.)*)"|namespace="(?<namespace>(?:[^"\\]|\\.)*)"|uri="(?<uri>(?:[^"\\]|\\.)*)"|response="(?<response>(?:[^"\\]|\\.)*)"|\w+="(?:[^"\\]|\\.)*"))*/
time_format %FT%T.%L%Z
</source>
<filter kubernetes.**>
@type kubernetes_metadata
@id filter_kube_metadata
</filter>
# Logs from systemd-journal for interesting services.
<source>
@type systemd
@id in_systemd_kubelet
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
pos_file /var/log/fluentd-journald-kubelet.pos
read_from_head true
tag kubelet
</source>
# Logs from docker-systemd
<source>
@type systemd
@id in_systemd_docker
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
pos_file /var/log/fluentd-journald-docker.pos
read_from_head true
tag docker.systemd
</source>
# Logs from systemd-journal for interesting services.
<source>
@type systemd
@id in_systemd_bootkube
filters [{ "_SYSTEMD_UNIT": "bootkube.service" }]
pos_file /var/log/fluentd-journald-bootkube.pos
read_from_head true
tag bootkube
</source>
image.tagを指定しているのはHelmのチャートだと以下のようなエンコードのエラーが出たので最新のタグにして合わせて設定ファイルも変えています。
2019-03-21 06:27:15 +0000 [warn]: temporarily failed to flush the buffer. next_retry=2019-03-21 06:36:28 +0000 error_class="Encoding::UndefinedConversionError" error="\"\\xC2\" from ASCII-8BIT to UTF-8" plugin_id="object:2b22921d2c68"
2019-03-21 06:27:15 +0000 [warn]: suppressed same stacktrace
以下のコマンドでKubernetesに反映します。
helm upgrade --install fluentd incubator/fluentd-cloudwatch -f helm/fluentd-cloudwatch-values.yaml
CloudWatch Logsにkubernetesというロググループができていれば正しく設定できています。
CloudWatch Logsのログをインサイトで確認する
ClouddWatch Logsはそのままだとポッドごとにファイルが別れてログストリームに出力されているので、ログストリームをクリックしても1つのポッドの出力しか確認できません。CloudWatch Logs Insightsでクエリ構文を使うことにより特定のデプロイメントの目的のログが取り出しやすくなります。
例えば以下のようなクエリを発行することによりkubernetes.var.log.containers.backend-*の@logStreamと2019-04-24T07:00:00.000+09:00〜2019-04-24T08:00:00.000+09:00の@timestampのフィルタに合致したバックエンドのログが10件出力できます。
fields @timestamp, @message, @logStream, @logStreamId
| filter @logStream like /kubernetes.var.log.containers.backend-/ and @timestamp >= 1556056800000 and @timestamp <= 1556060400000
| sort @timestamp desc
| limit 10
CircleCIで自動デプロイする
ローカルの環境だと、kubectl apply -f ...を使ったりHelmを使ったりしてデプロイしますがいちいちやると手間なのでCircleCIを使ってdevelopブランチにコミットがプッシュされるたびにKubernetsにデプロイされるように設定します。
CircleCIはビルドのたびに$CIRCLE_SHA1というハッシュが付与されるのでイメージをビルドしてタグを$CIRCLE_SHA1でつけておきます。
あらかじめAWSの設定をCircleCI上にしてから、抜粋ですが以下のようにするといいかなと思います。
kubectl apply -f ...にすきなKubernetesのファイルを反映させてください(ファイルのイメージのタグをsedかなにかで$CIRCLE_SHA1とあらかじめ置換しておいてください)。この置換がいまいちな場合はHelmのチャートにするのも手です。
deploy:
docker:
- image: circleci/python:2.7-jessie
steps:
- checkout
- run:
name: Install AWS CLI
command: sudo pip install awscli
- run:
name: Install kubectl CLI
command: |
mkdir ./bin
curl -o kubectl https://amazon-eks.s3-us-west-2.amazonaws.com/1.11.9/2019-03-27/bin/linux/amd64/kubectl
chmod +x ./kubectl
mv kubectl ./bin/kubectl
curl -o aws-iam-authenticator https://amazon-eks.s3-us-west-2.amazonaws.com/1.12.7/2019-03-27/bin/linux/amd64/aws-iam-authenticator
chmod +x ./aws-iam-authenticator
mv aws-iam-authenticator ./bin/aws-iam-authenticator
echo 'export PATH="./bin:$PATH"' >> $BASH_ENV
- run:
name: Check kubectl command
command: |
aws eks update-kubeconfig --name eks-cluster-name
kubectl apply -f ...
ノードにノードラベルを設定する
Worker Nodesの手順でノードは追加できますがnode-labelsをつけるには、CloudFormationのBootstrapArgumentsに以下のように記載します。
--kubelet-extra-args --node-labels=nodegroup=analytics
ワーカーノードを追加する
新しいワーカーノードは普通に1つめのワーカーノードと同じように作ればいいのですが以下の追加作業があるので忘れないようにします
- kube2iamを使っている場合、IAMのロールの信頼を更新
- ワーカーノード間のDNSや通信を通すためセキュリティーグループでお互いに疎通できるようにする
Datadogで監視する
Deploying Datadog in Kubernetes using HelmにあるようにHelmで入れることができます。ただこれだと開発用・本番用など複数のクラスタに入れたときに区別できなくて困るので、ここにあるようにIAMを設定してEKSのクラスタ名をとれるようにする必要があります。
まとめ
EKSでの運用に役立つ情報を紹介しました。まだまだあると思うので気づいたら追記していきます。