EKS(Kubernetes)上にDigdag・Embulk・Redashで分析環境を構築する
Kubernetes上に分析環境を構築する機会があったのでどのように構築したかを紹介します。同じような構成でKubernetes上で構築するのは3回目になったので構築方法も洗練されてきました。構成は以下のようになっています。
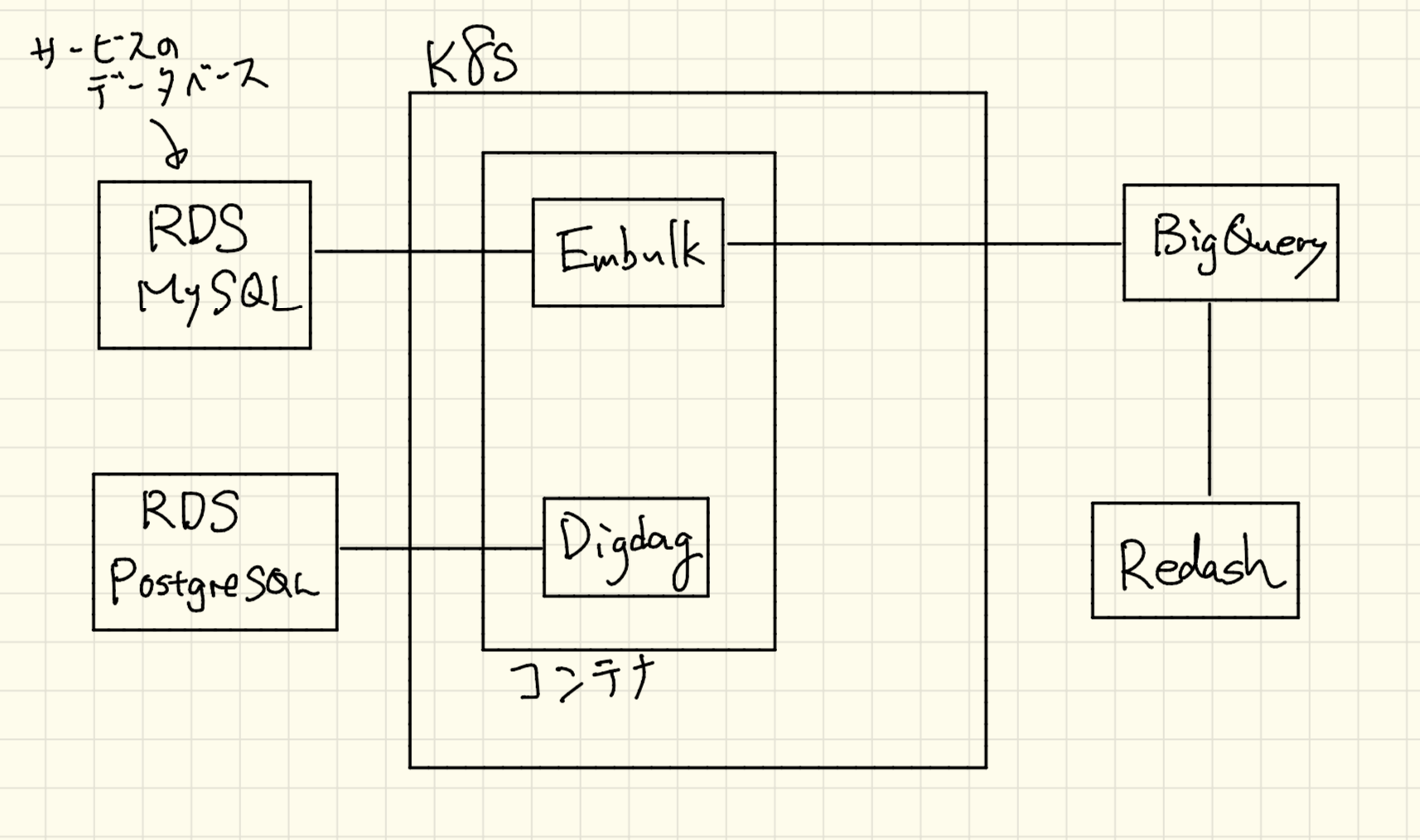
- MySQL(RDS): サービスのデータベース。ここのテーブルからBigQueryにEmbulkでデータをエクスポートします。
- PostgreSQL(RDS): Digdagのデータベース。今回新たにつくりました。
- Digdag: データベースのエクスポートなどを実行するタスクスケジューラ。失敗したときにリトライもできます。
- Embulk: プラグインを使ってデータベースをMySQLからBigQueryにエクスポートします。Digdagと同じDockerコンテナでDigdagのタスクから実行されます。
- BigQuery: すべてのエクスポートされたデータをここに集約させます。
- Redash: Redashは自分達で構築せずにRedash as a Serviceを使いました。普通に使う分には$99/月と値段がそんなに高くないのでメンテナンスコストなども考え選択しました。
Kubernetes側で構築するのはDigdagとEmbulkだけです。
ワーカーノードの作成
EKSは構築されている前提なので、分析環境用のワーカーノードを作成します。基本的にここの手順ですが、変更したところを書きます。
- NodeGroup:
analytics-20190330としました。今後新しいノードグループを作ることもあるのと思うので日付をグループ名に入れてあります。 - ノードのサイズ: 1にしてあります。1台でリソース大丈夫かなと思っていますが必要なら増やしてください。
- NodeInstanceType:
t3.largeです。ここらへんもあまり小さいインスタンスサイズでないものを適当に選んでください。 - NodeVolumeSize: 100GBにしてあります。ここも適度に大きければ大丈夫です。
ワーカーノードをクラスターと結合したら以下のコマンドでノードがクラスタ上で表示されるか確認してみます。STATUSがReadyになっていたら大丈夫です。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-XXX-XXX.ap-northeast-1.compute.internal Ready <none> 1m v1.11.9
DigdagとEmbulkのDockerビルド
DigdagでEmbulkを動かすのでDigdagとEmbulkがはいったDockerfileを作ります。
以下のフォルダ構成です。
├── Dockerfile
└── digdag
├── digdag.properties
├── embulk_configs
│ └── jobs.yml.liquid
└── mysql_backup.dig
DockerfileでEmbulkとDigdagをインストールします。特に変わったことはしていないです。
FROM azul/zulu-openjdk:8
ENV EMBULK_VERSION=0.9.17
ENV DIGDAG_VERSION=0.9.35
# install embulk
RUN apt-get -y update && \
apt-get -y upgrade && \
apt-get -y install locales && \
apt-get -y install curl && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
# timezone (Asia/Tokyo)
ENV TZ JST-9
RUN curl -o /usr/local/bin/embulk --create-dirs -L "https://dl.bintray.com/embulk/maven/embulk-$EMBULK_VERSION.jar" && \
chmod +x /usr/local/bin/embulk
# install digdag
RUN curl -o /usr/local/bin/digdag --create-dirs -L "https://dl.digdag.io/digdag-${DIGDAG_VERSION}" && \
chmod +x /usr/local/bin/digdag && \
apt-get clean && rm -rf /var/cache/apt/archives/* /var/lib/apt/lists/* && \
adduser --shell /sbin/nologin --disabled-password --gecos "" digdag
USER digdag
WORKDIR /home/digdag
ENV PATH=${PATH}:/usr/local/bin
RUN /usr/local/bin/embulk gem install embulk-input-mysql && embulk gem install embulk-output-bigquery
COPY digdag .
EXPOSE 65432
CMD ["sh","-c", "java -jar /usr/local/bin/digdag server -c digdag.properties --task-log /var/tmp --max-task-threads 4"]
digdag.propertiesにはDigdagの設定情報を記載します。database.*の情報は先に説明したDigdag用のRDSの設定を保存してください。digdag.secret-encryption-key は16文字の英数字をbase64でエンコードした値をシークレットキーとして記載してください。echo UDZDcTTmD7uwm3Av | base64のように実行すればエンコードされた値を取得できます。
server.bind = 0.0.0.0
database.type = postgresql
database.user = postgres
database.password = password
database.host = xxxx
database.database = digdag
database.maximumPoolSize = 4
digdag.secret-encryption-key = VURaRGNUVG1EN3V3bTNBdgo=
embulk_configs/jobs.yml.liquidにはMySQLからBigQueryへのエクスポート設定を書きます。今回のデータベースの時間がUTCだったのでUTCで設定しています。各種環境変数で設定してステージング・本番で変更できるようにしてあります。ここらへんの設定に関してはDigdagのembulk-input-jdbcや、embulk-output-bigqueryを見るといいかなと思います。
in:
options: {useLegacyDatetimeCode: false, serverTimezone: UTC}
default_timezone: "UTC"
type: mysql
host: {{ env.EMBULK_INPUT_MYSQL_HOST }}
user: {{ env.EMBULK_INPUT_MYSQL_USER }}
password: {{ env.EMBULK_INPUT_MYSQL_PASSWORD }}
database: {{ env.EMBULK_INPUT_MYSQL_DB }}
table: jobs
out:
type: bigquery
auth_method: json_key
json_keyfile: {{ env.EMBULK_OUTPUT_KEY_FILEPATH }}
mode: replace
dataset: {{ env.EMBULK_OUTPUT_DATASET }}
table: jobs
auto_create_table: true
source_format: CSV
max_bad_records: 0
allow_quoted_newlines: 1
mysql_backup.digにはDigdagで動かすタスクの設定を記載します。毎日2時(日本時間)にembulk_configs/jobs.yml.liquidを実行します。リトライ処理も入れてあります。
timezone: Asia/Tokyo
schedule:
daily>: 02:00:00
+step1:
loop>: 1
_do:
_parallel: false
+projects:
_retry: 5
sh>: embulk run embulk_configs/jobs.yml.liquid
設定ファイルを編集したらDockerでビルドします。今回は以下のようにビルドし、ECRにプッシュしておきます。
docker build -t xxx.dkr.ecr.ap-northeast-1.amazonaws.com/analytics:1.0.0 .
docker push xxx.dkr.ecr.ap-northeast-1.amazonaws.com/analytics:1.0.0
KubernetesにDigdag/Embulkをデプロイ
Kubernetes用のDeploymentを作ってデプロイします。まずDeploymentのファイルをつくります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: digdag
spec:
replicas: 1
selector:
matchLabels:
app: digdag
template:
metadata:
labels:
app: digdag
spec:
containers:
- name: digdag
image: xxx.dkr.ecr.ap-northeast-1.amazonaws.com/analytics:1.0.0
command: ["java", "-jar", "/usr/local/bin/digdag", "server", "-c", "digdag.properties", "--task-log", "/var/tmp", "--max-task-threads", "4"]
env:
- name: EMBULK_INPUT_MYSQL_HOST
value: mysql_host
- name: EMBULK_INPUT_MYSQL_USER
value: root
- name: EMBULK_INPUT_MYSQL_PASSWORD
value: password
- name: EMBULK_INPUT_MYSQL_DB
value: db
- name: EMBULK_OUTPUT_KEY_FILEPATH
value: /secrets/digdag.json
- name: EMBULK_OUTPUT_DATASET
value: database_export
volumeMounts:
- name: analytics-credentials
mountPath: /secrets
readOnly: true
ports:
- containerPort: 65432
volumes:
- name: analytics-credentials
secret:
secretName: analytics-credentials
EMBULK_INPUT_MYSQL_HOSTなどのMySQL関係の環境変数はエクスポートしたいMySQLの情報を設定してください。EMBULK_OUTPUT_KEY_FILEPATHでGCPのサービスアカウントのJSONキーの位置を指定しています。これは後述しますがKubernetesのシークレットの仕組みを使ってファイルを保存したものをマウントしています。EMBULK_OUTPUT_DATASETはBigQueryのデータセット名です。あらかじめ作っておいてください。
analytics-credentialsというシークレットをあらかじめ作る必要があるので以下のように作ります。gcp-service-account-key.jsonはサービスアカウントのキーです。
kubectl create secret generic analytics-credentials --from-file=digdag.json=gcp-service-account-key.json
作り終わったらデプロイします。
kubectl apply -f analytics.yaml
しばらくしてポッドが立ち上がったらDigdagのポッドに入ってタスクを設定します。
# ポッドに入る
kubectl exec -it $(kubectl get pod -l app=digdag -o jsonpath='{.items[0].metadata.name}') bash
# ポッドのシェル上で以下を実行
digdag push scheduler
これでDigdagの設定は完了したのでDigdagのポッドにポートフォーワードしてローカルからブラウザでhttp://localhost:65432にアクセスしDigdagの管理画面がみれたら完了です。
kubectl port-forward $(kubectl get pod -l app=digdag -o jsonpath='{.items[0].metadata.name}') 65432:65432
Redashの導入
Redash as a Serviceは無料期間があるので有料がいやだなと思う人はそれで試してみるといいかなと思います。登録したらBigQueryのデータソースを登録します。

設定のJSON Key FileはGCPのウェブコンソールからサービスカウントを作ってBigQuery AdminをつけてからJSONキーを取得したものを設定してください。
まとめ
DockerとKubernetesを使うことによりすばやく分析環境が構築できました。分析したいけどデータがちらばっていてどうしたらいいかわからないという場合は、DigdagとEmbulkを使って各データベースなどの情報をBigQueryに流してRedashで分析すると効率的にサービス改善ができます。EmbulkからBigQueryへのエクスポートはときどき失敗するのですが、Digdagを使うことによりリトライができ失敗確率も減り安心して開発に専念できます。
Digdagは他にもBigQueryのクエリを実行してその結果をBigQueryに保存するということを定期的に行えば中間テーブルを日別に生成できるので便利です。
よさそうだと思ったらぜひ、Embulk・Digdag・Redashの組み合わせを試してみてください。