GKEをCloud MonitoringとPrometheusでちゃんと監視する
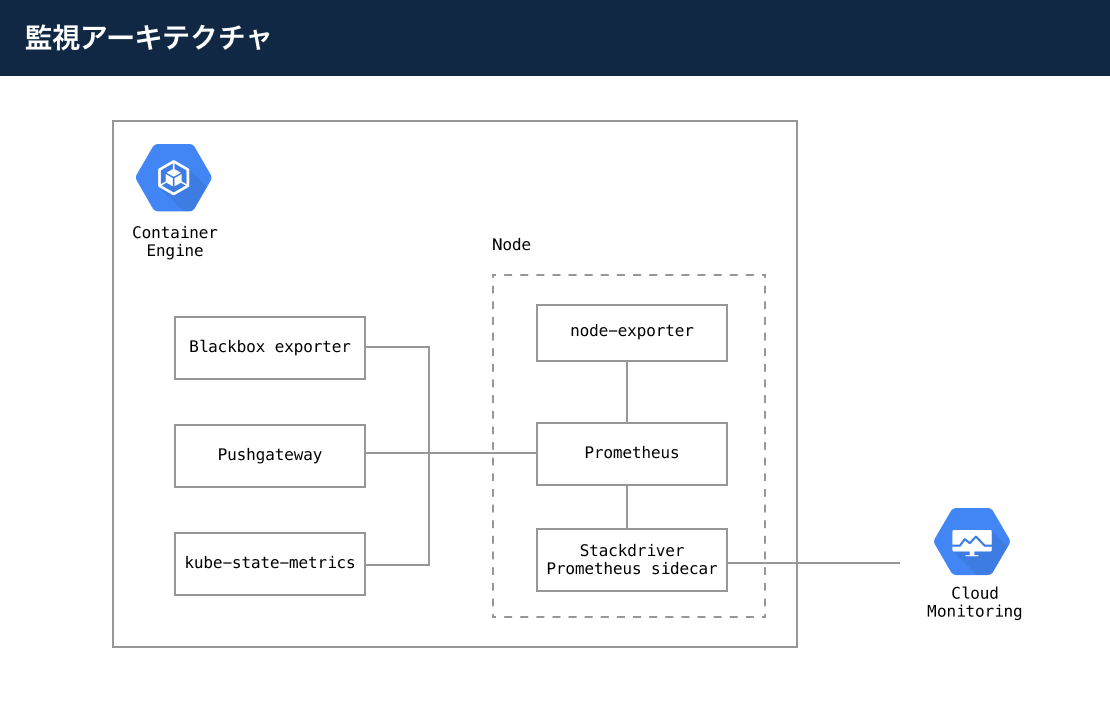
ここ2週間くらい10XでGKEの監視を整えています。2年前にタベリーで監視を整えたときよりだいぶいい感じに作れたのでどのようにしたか紹介したいと思います。全体的な構成は以下のようになっています。
Kubernetesの監視は大変
Kubernetesで監視を設定していて、毎回大変だなーと思っていたのですが以下の理由があります。
- 通常の監視に加えて、Kubernetes自体のメトリックスも監視する必要がある
- Kubernetes自体のメトリックスを監視するのにkube-state-metricsなど別途サービスを入れる必要がある
- 多くのメトリックスが取得されるので保存と可視化が面倒
一般的にはPrometheusとGrafanaの組み合わせか、DatadogなどSaaSを導入するかになるかと思います。
タベリーでは、PrometheusとGrafanaでやっていますがメトリックスを保存するためにPVC(Persistent Volume Claim)でディスクを用意しバックアップしたりと運用しなければいけません。さらに30日などの長期間のメトリックスを待つことなく表示させるためにパフォーマンスにも気をつけなければならないので面倒です。
Datadogを使う方法では簡単に導入できるのですが費用が結構かかります。この費用をまかなえる場合は迷わずDatadogを使ったほうがいいでしょう。
Cloud Monitoringだけで監視はできないか
GCPにはCloud Monitoring(Stackdriver)があるのでこれだけでKubernetesが監視できないものでしょうか。いろいろ試したのですが現在の状態では難しいかなと思います。そもそもほしいメトリックスが足りていません。例えば、kube-state-metricsで取得できるCronJobの実行時間や成功・失敗のメトリックスがありません。カスタマイズされたメトリックスを送るにしてもモニタリングエージェントをインストールせねばならず手間です。
Cloud MonitoringでGKEをちゃんと監視するにはどうしたらいいか
Prometheusでメトリックスを収集しCloud Monitoringに送信、Cloud Monitoringでメトリックスの保存・可視化・アラートの設定を行うことでGKEをちゃんと監視できるようになりました。Prometheusでメトリックスを収集することにより、kube-state-metricsなど既存で有用なKubernetesのメトリックスが簡単に集めることができます。Stackdriverにメトリックスを保存することによりKubernetes側でディスクを管理することもなくなりパフォーマンスの問題からも開放されました。
どのように実現したか
監視アーキテクチャは以下になります(再掲)
- Prometheus: 各所からメトリックスを収集します。PrometheusのArchitectureにPrometheusがどのようなコンポーネントで構成されているか記載されています。
- Stackdriver Prometheus sidecar: このsidecarを使うところが今回のポイントです。Prometheusに集められたメトリックスをCloud Monitoringにエクスポートできます。必要なメトリックスだけ指定してエクスポートすることもできるので不要なデータを送らないですみます。
- Node exporter: KubernetesのノードのハードウェアやOSのメトリックスを取得します。
- Blackbox exporter: サービスの死活監視ができます。例えば、https://example.com などと指定してそのサーバがレスポンスを返してくるかどうかを監視できます。その他にも証明書の期限が切れるのはいつかもメトリックスとしてあります。
- Prometheus Pushgateway: PrometheusにPushgatewayのREST APIを通してメトリックスを送ることがきます。 PrometheusはPrometheus自体が他のexporterからメトリックスを取りに行くpull方式ですが、CronJobなどのバッチ処理の場合、pullされるポートがひらいているわけではないので、このPushgatewayにCronJobがメトリックスをpushすることによりPrometheusにメトリックスを送ることができます。ここにpushばっかりするとパフォーマンスが悪くなるのであくまで補助的な位置付けですがpushできるのは便利です。
- kube-state-metrics: PodやCronJobなどKubernetesの多数のメトリックスが取得できます。docsにメトリックスの一覧がありますがinternal/store以下のソースコードをみたほうが早いかもしれません。
上記のように構成することでPrometheusでメトリックスを保存し、Cloud Monitoringにメトリックスが送られて保存され、可視化もできるようになりました。
インストール方法
以下の環境を前提とします
- GKE: 1.15.9-gke.8
- Helm: v3.1.1
- Prometheus: 11.0.1(Chart version), 2.16.0(App version)
基本的にHelmでインストールしていきます。
PrometheusとStackdriver Prometheus sidecar
PrometheusのHelm ChartとGCPのStackdriver Prometheus sidecarのインストール方法ドキュメントに個別のインストール方法があるのであらかじめ確認して全体の流れをつかんでおきます。
それではインストールしていきます。
PrometheusとStackdriver Prometheus sidecarをHelmでインストールするための設定ファイルであるvalues.yamlを作ります。
server:
service:
type: NodePort
persistentVolume:
enabled: false
kubeStateMetrics:
enabled: true
nodeExporter:
enabled: true
alertmanager:
enabled: false
server:
sidecarContainers:
- name: sidecar
image: gcr.io/stackdriver-prometheus/stackdriver-prometheus-sidecar:0.7.3
imagePullPolicy: Always
args:
- "--stackdriver.project-id=project-id"
- "--prometheus.wal-directory=/data/wal"
- "--stackdriver.kubernetes.location=asia-northeast1-a"
- "--stackdriver.kubernetes.cluster-name=cluster-name"
- "--include={__name__=~\"kube_job_status_failed|container_cpu_usage_seconds_total|container_memory_working_set_bytes|container_cpu_cfs_throttled_seconds_total|kube_pod_container_resource_requests_cpu_cores|kube_pod_container_resource_limits_cpu_cores|kube_pod_container_resource_requests_memory_bytes|kube_pod_container_resource_limits_memory_bytes|container_network_receive_bytes_total|container_network_transmit_bytes_total|container_network_receive_packets_dropped_total|container_network_transmit_packets_dropped_total|node_filefd_allocated|kube_pod_container_status_restarts_total|probe_ssl_earliest_cert_expiry_days|prometheus/probe_dns_lookup_time_seconds\"}"
- "--log.level=debug"
- "--stackdriver.generic.location=asia-northeast1-a"
- "--stackdriver.generic.namespace=default"
- "--config-file=/etc/config/config.yaml"
ports:
- name: sidecar
containerPort: 9091
volumeMounts:
- name: storage-volume
mountPath: "/data"
serverFiles:
prometheus.yml:
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: 'kubernetes-nodes'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/$1/proxy/metrics
- job_name: 'kubernetes-nodes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labeldrop
regex: __meta_kubernetes_service_label_(.+)
- action: labeldrop
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
metric_relabel_configs:
- source_labels: [job_name]
action: replace
regex: ([a-z\-]+)-(\d+)
replacement: $1
target_label: job_short_name
- job_name: 'kubernetes-service-endpoints-slow'
scrape_interval: 5m
scrape_timeout: 30s
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape_slow]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
- job_name: 'prometheus-pushgateway'
honor_labels: true
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: pushgateway
- job_name: 'kubernetes-services'
metrics_path: /probe
params:
module: [http_2xx]
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'kubernetes-pods-slow'
scrape_interval: 5m
scrape_timeout: 30s
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
- job_name: 'blackbox-exporter'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
- https://example.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:9115 # Blackbox exporter.
各項目はPrometheusのHelm Chartで詳しくみていただくとして、重要な点は、sidecarContainersとして、Stackdriver Prometheus sidecarをPrometheusのsidecarとしてインストールしてあります。server.persistentVolume.enabledがfalseになっているのは、sidecarがPrometheusと同じディスクを参照するのでPV(PersistentVolume)のaccessModesがReadWriteManyでないとエラーになってしまいます。GKEでPersistenteVolumeでは通常ReadWriteOnceしかつくれないので、2つのコンテナから利用できません。つまりこのPrometheusは長期的にデータを保存するものではなくCloud Monitoringにデータを送るためのハブとして利用しています。デプロイされ更新されるとPrometheus自体に溜まっていたデータは当然データは消えてしまいます。
sidecarの--includeオプションにはCloud MonitoringにExportしたいメトリックスを入れます。ここが増えすぎると料金がかさむので気をつけます。
その他デフォルトの設定と変えているところとしては、適宜、PrometheusからCloud Monitoringに送る際のラベルの数をlabeldropで設定して落としています。Cloud Monitoringは10ラベルを超えたメトリックスを受けるとエラーになるのでいらなさそうなラベルや値がかぶっているラベルは落としています。
kubeStateMetricsとnodeExporterはPrometheusと一緒に入れれるのでenabledをtrueにしておきます。
アラートは、Cloud Monitoringのものを使うのでalertmanagerのenabledはfalseにしておきます。
sidecarの設定(--stackdriver.project-idなど)やBlackbox exporterの設定は適宜環境に合わせて変更し、確認したら、values.yamlの設定を以下のコマンドでインストールします。
helm upgrade --install prometheus --namespace default stable/prometheus --values kubernetes/prometheus/values.yaml
上記でPrometheusがインストールされます。
Blackbox nodeExporter
以下のようにvalues.yamlを作ります。fullnameOverrideを変えているのはPrometheusの設定の job_name: 'blackbox-exporter'と一致せるためです。
fullnameOverride: 'blackbox-exporter'
以下でインストールできます
helm upgrade --install prometheus-blackbox-exporter --namespace default stable/prometheus-blackbox-exporter -f values.yaml --debug
Prometheusの値をただCloud Monitoringに送るだけでは物足りない
Prometheusの値をそのままCloud Monitoringに送るだけでは足りないときがあります。例えば、Blackbox exporterの証明書の期限が切れる日を表すprobe_ssl_earliest_cert_expiryは1591068102のように切れる日付で返ってきます。アラートを設定するにはあと何日で切れるという情報を保持し、20日以下なら警告するということがしたいはずなので日付では困ります。Prometheusの場合は(probe_ssl_earliest_cert_expiry - time()) / 86400とクエリを実行すれば取得できるのですが、Cloud Monitoringではそのような演算方法がありません。
この何日で切れるという情報をCloud Monitoringでも利用できるようにするために、PrometheusのRecoding rulesを使います。Recording rulesは定期的にPrometheusのクエリを実行しその結果を新しいメトリックスとして保存することができます。メトリックスとして保存できればsidecarによりCloud Monitoringに送られるので目的が達成できます。
ここのI'm using recording rules and the metrics don't appear in Cloud Monitoring.にも書いてあるのですが、Recording rulesを設定した場合、static_metadataにmetricを設定しないとsidecarからCloud Monitoringに送られません。
それでは設定していきます。
まずsidecar用にConfigMapを作ります。
apiVersion: v1
kind: ConfigMap
metadata:
name: stackdriver-prometheus-sidecar-config
namespace: default
data:
config.yaml: |
static_metadata:
- metric: probe_ssl_earliest_cert_expiry_days
type: gauge
help: "GAUGE: Returns earliest SSL cert expiry in days"
kubectlで適用します。
kubectl apply -f configmap.yaml
Prometheusのvalues.yamlを変更します。変更箇所だけのせます。
server:
...
extraVolumes:
- configMap:
name: stackdriver-prometheus-sidecar-config
name: stackdriver-prometheus-sidecar-config
serverFiles:
recording_rules.yml:
groups:
- name: blackbox-exporter-refinement
rules:
- record: "probe_ssl_earliest_cert_expiry_days"
expr: (probe_ssl_earliest_cert_expiry - time()) / 86400
...
server:
sidecarContainers:
- name: sidecar
...
volumeMounts:
...
- name: stackdriver-prometheus-sidecar-config
mountPath: "/etc/config"
readOnly: true
以前のと同じHelmでPrometheusに適用します。
Cloud Monitoringでどのように監視できるか
GCPコンソールのMonitoring > Dashboardsからダッシュボードが確認できます。
既存のKubernetes Engineダッシュボード
こちらは既存であるGKEのメトリックスダッシュボードです。今回のsidecarの設定をしなくても存在している既存のものです。
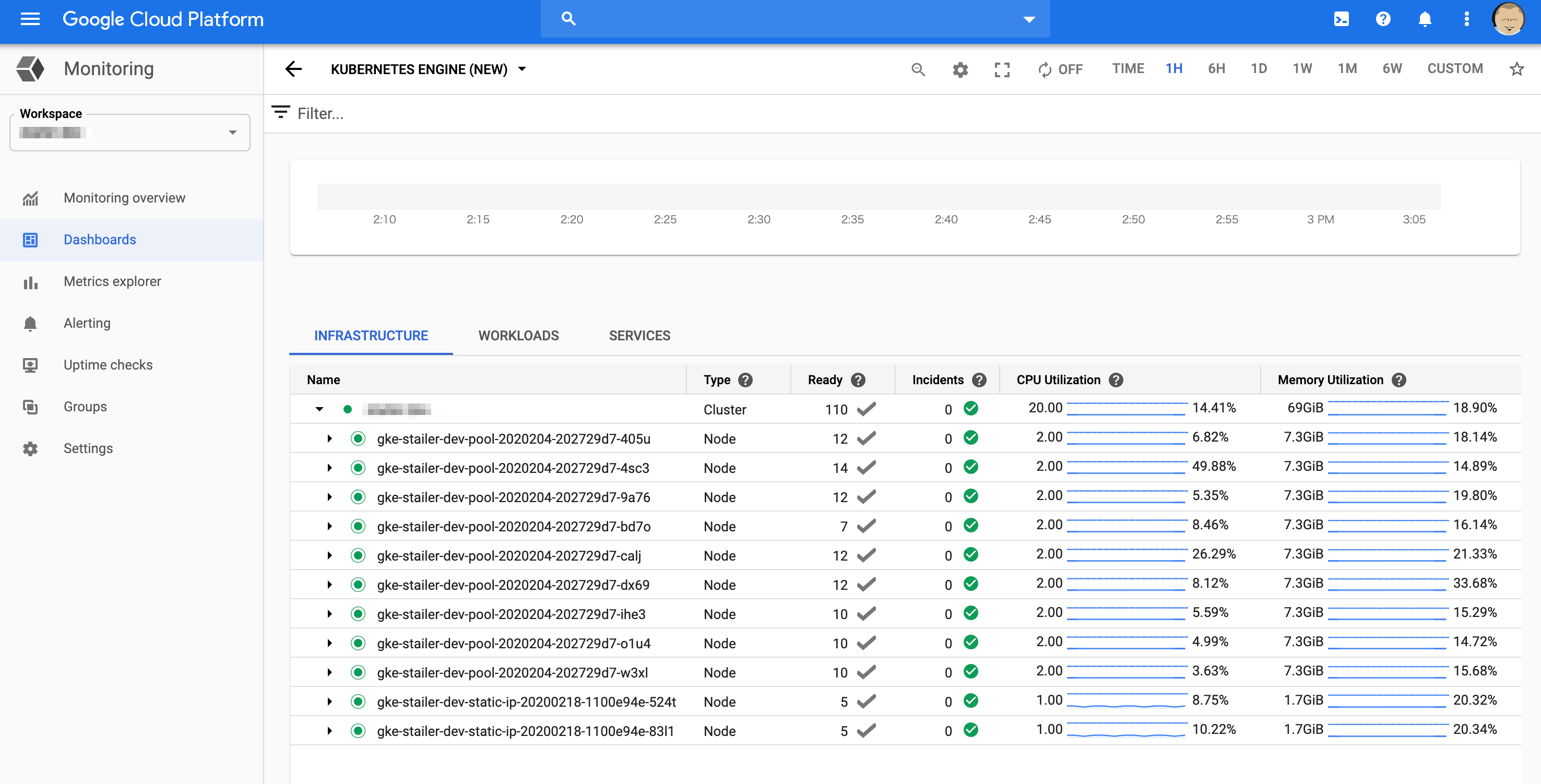
ネストされた項目をひらいていくと以下のように各ポッドのメトリックスがみれます。
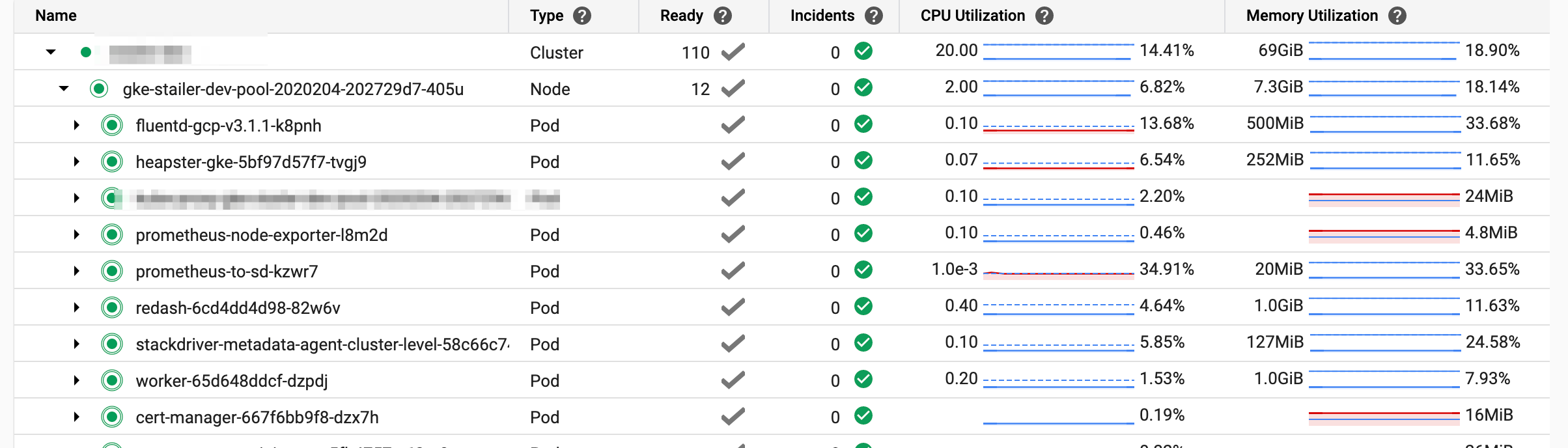
ざっくりとしたノード・ポッドのCPU UsageとかMemory Usageとかをみたいときはこちらを利用します。ただ、CPU UtilizationがRequestあたりの割合だったりと絶対値が知りたいときに不便だったりします。
Prometheusのデータとともに作成されたダッシュボード
PrometheusからCloud Monitoringにメトリックスが送られるようになったので、GCPコンソールのMonitoring > Metrics explorerから各種グラフを作成しダッシュボードにすることができます。
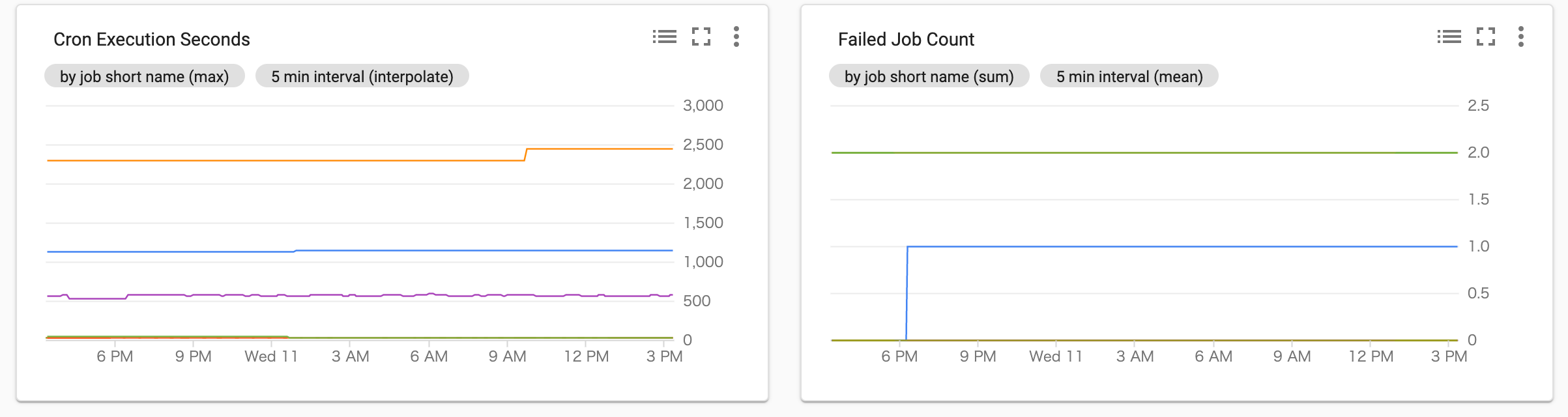
証明書の期限切れまでの日数であるprobe_ssl_earliest_cert_expiry_daysは以下のようにグラフを作成しダッシュボードに追加することができます。
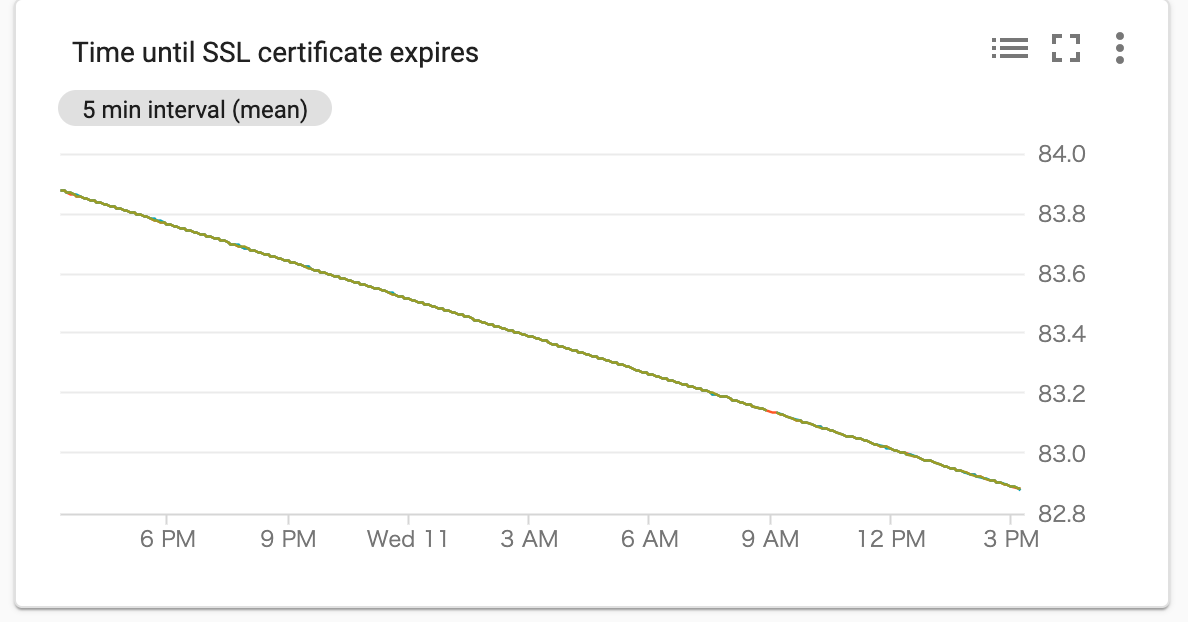
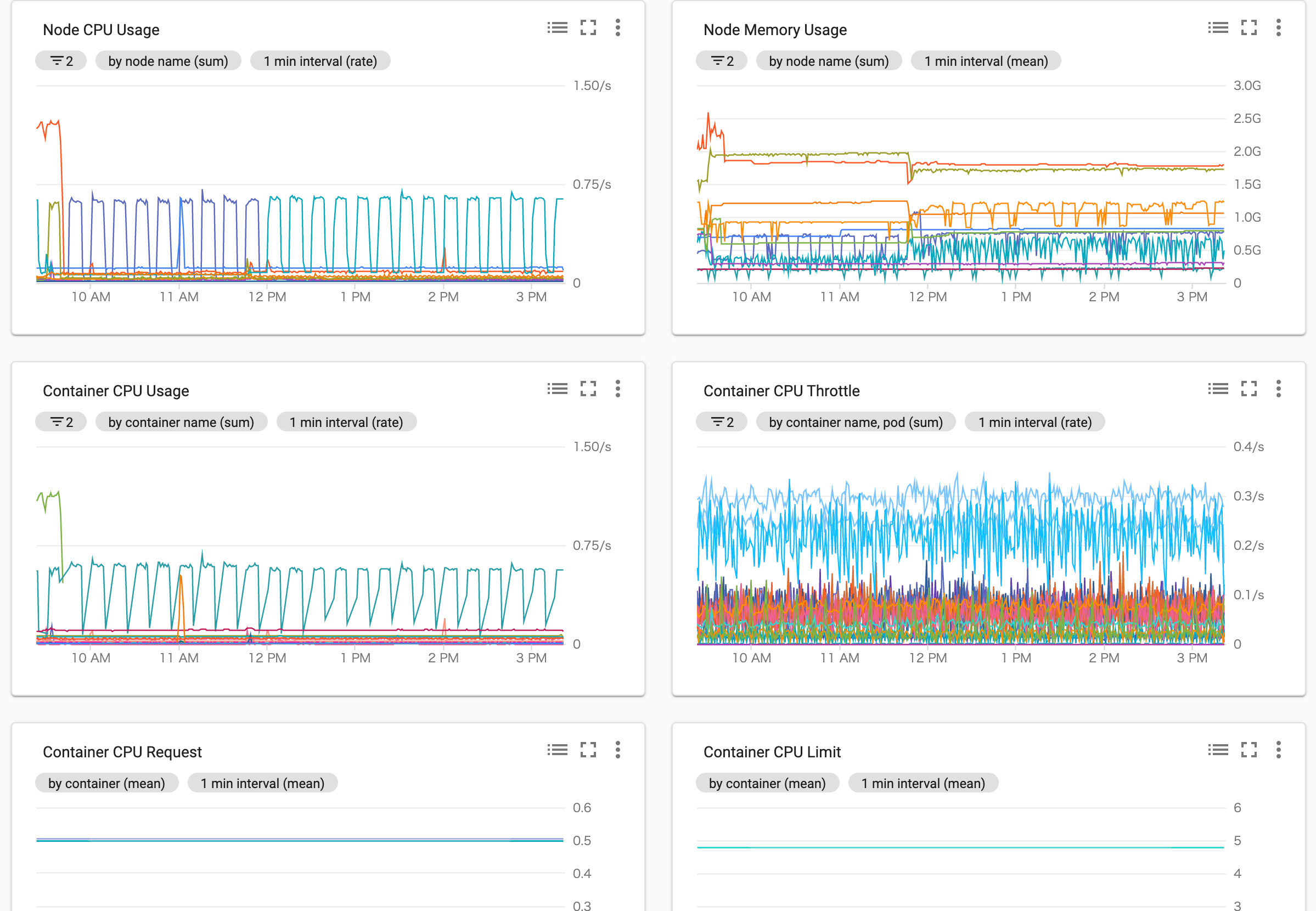
そのほか、CronJobの実行時間や失敗したジョブの数、ノード・コンテナのサービスごとのCPU/Memory/Network/Diskなど簡単にグラフにしてダッシュボードを作成できます。
Kubernetesでどのようなメトリックスを取得したらいいかは以下を参考としてリンクしておきます。
- https://speakerdeck.com/yosshi_/kuberntes-monitoring-ru-men
- https://itnext.io/k8s-monitor-pod-cpu-and-memory-usage-with-prometheus-28eec6d84729
複数環境でダッシュボードをどのように同期するか
ここまで1つの環境(たとえば開発環境)でのCloud Monitoringのダッシュボードの作成はできましたが、複数環境(たとえばプロダクション・ステージング環境両方)ある場合は、1つの環境で作ったダッシュボードをどのように他の環境へコピーすればいいのでしょうか。
Stackdriver Cloud Monitoring Dashboards API のご紹介に書いてあるのですが、Cloud Monitoring Dashboard APIでダッシュボードを他の環境へコピーすることができます。
ListDashboardsでダッシュボード一覧を取得し、他の環境にCreateDashboardまたは既存のダッシュボードを上書きしたい場合はUpdateDashboardで上書きできます。
自分はgRPC APIでやりましたがREST APIもあります。
アラートの設定
アラートはGCPコンソールのMonitoring > Alertingからできます。直感的なのでとくに説明はいらないと思いますが、DashboardのグラフからMonitoringが作成できないのは非常に不便です。
まとめ
GKEのモニタリングの方法としてPrometheusからCloud Monitoringにメトリックスをエクスポートする方法を紹介しました。Prometheusの柔軟性を活かしつつ運用コストの低いCloud Monitoringを使うことでいいかんじにGKEを監視することができました。