CSVの内容を検証するtable-validatorというnpmパッケージを作りました
この記事は 🎄10X プロダクトアドベントカレンダー2023 の24日目(12/24)の記事です!昨日は、小迫(@aki85135)さんの「エンタープライズプラットフォームの開発には何が必要なのか?」という記事を公開しています。
本日は、SWEの@wapa5powが担当します。CSVに悩まされたことがあるSWEのための記事です。
背景
10Xが開発しているStailer(小売チェーン向けECプラットフォーム)は外部パートナーとファイル連携をよく行ないます。 すぐ思いつくだけでも以下のケースがあります。
- 商品の売り場を作るマスタインポート
- 基幹からCSVのファイルをGCS(Google Cloud Storage)に配置
- 管理画面からCSVのファイルをアップロード
- 配送エリアの設定
- システムリプレイス時に既存のシステムから引き継ぎ情報をインポート
- ポイント連携
CSVを連携するのはいいのですがCSVはテキストファイルなのでよく間違っていることがあります。
- 特定のカラム(IDなど)がユニークになっていなければいけないのに重複している
- 1~4の値しか入っていてはいけないのに異なる値が入っている
- 整数しか入っていてはいけないのに小数がはいっている
- 日付が入っているはずだが2/31などありえない日付が入っている
経験したことがある人には思い出すだけで、ウッとなると思います。
不正なファイルがあると、アラートが上がったり、お問い合わせがあったりして対応する必要があります。 その場合、どこが間違っているか確認して先方に連絡する必要があります。 先方は連絡を受けてから修正してシステムに反映します。とても対応工数が高いです。
連携方法の整理
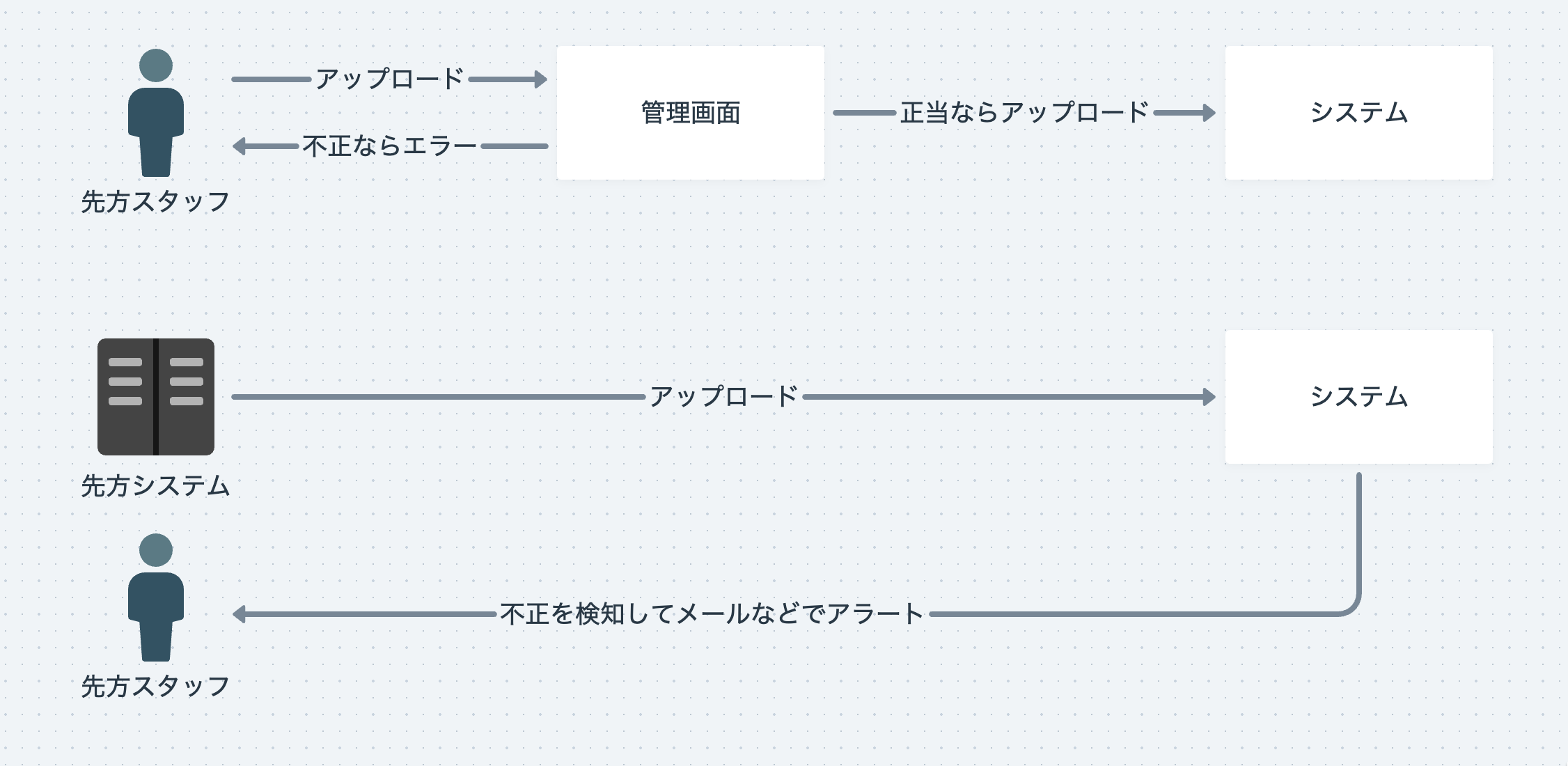
ありとあらゆるところから連携されるファイルですがシステムに連携するはまとめると以下しかありません。
- 人が管理画面からアップロードする
- システムがアップロードする
ファイルは連携されたら、連携元ができるだけ早く不正なファイルを連携してしまったと気づいてもらいたいです。そうすると連携先の手間がなくなります。 管理画面からアップロードの場合、そもそも不正なファイルはアップロードされないようにしたいです。 システムのファイル連携の場合、配置されたのを検知して不正なファイルなら連携元に通知するようにしたです。
CSVの内容を検証するtable-validatorを作る
管理画面からアップロードするときにブラウザ上で検証するにはnpmパッケージが良さそうです。 システムがアップロードする場合も、ファイルが置かれたのを契機に何らかしらの処理を行うのにも同じようにnpmパッケージが使えると良さそうです。
ということで試しにtable-validatorを作ってみました。(最初csvvという名前で作っていたのですがすでにnpmパッケージであったのでこの名前になりました。)
Demoを見ると早いと思いますのでアクセスして、Validateボタンを押して見てください。
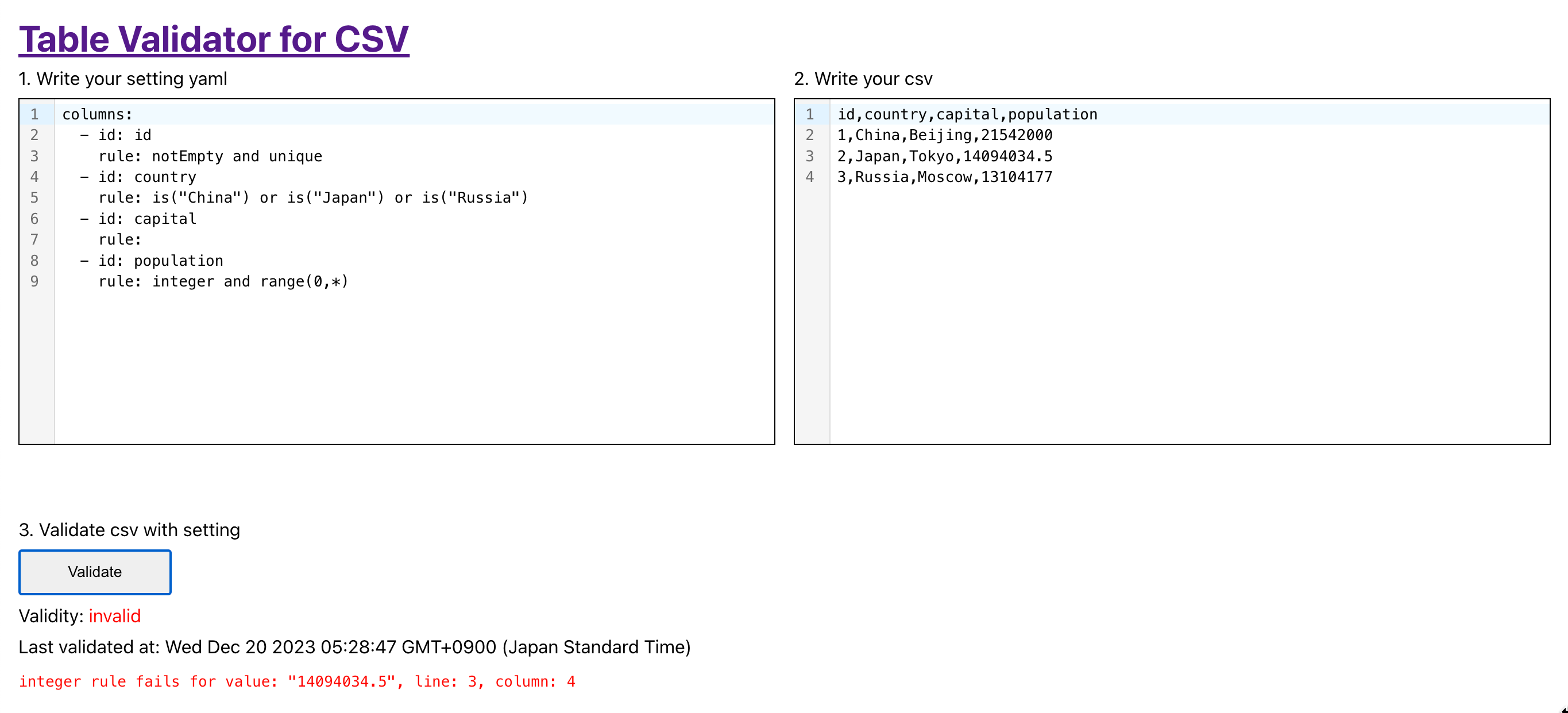
Validateを押すと左上のYAMLで書かれたスキーマに、右上のCSVが正当かの検証をします。
正当なCSVであればvalidが、不正ならinvalidと出ます。
上記の例では、3行目( line: 3 ) の4列目( column: 4 )の14094034.5が整数を期待しているのに小数になっているというエラーです。
YAMLのスキーマさえあればCSVが検証できます。このスキーマはSWE(Software Engineer)でなくても書けるというところがポイントです。 zodで書けばいいという話もありますが、ファイル連携が決まるたびにSWEが型を定義してコードを書くのが通常ですが、ファイル連携は数が多くなりがちなので定義自体を誰でもかけるようにしておくとSWEの工数を削減できます。
スキーマについて
デモ画面の左上ではYAMLでCSV検証のためのスキーマを書きます。
columns:
- id: id
rule: notEmpty and unique
- id: country
rule: is("China") or is("Japan") or is("Russia")
- id: capital
rule:
- id: population
rule: integer and range(0,*)
columns: にはCSVのカラム数分検証するルールを書きます。上記は4つのルールがあるので4列のCSVファイルです。
ルールがない場合は rule: を空にするか - だけ書いても大丈夫です。詳しいルールはREADMEに記載しました。
今のところ以下のルールがあります。
| ルール | 例 | 例の説明 |
| ---- | ---- | ---- |
| notEmpty | notEmpty | 空文字でない |
| empty | empty| 空文字のみ | | is |is("Japan")| Japanに一致 | | any |any("Japan", "France")| JapanかFranceに一致 | | not |not("Tokyo")| Tokyoならエラー | | unique |unique| 列の値がすべてユニーク | | range |range(10,20)| 値が10以上20以下 | | length |length(2,10)| 文字列長が2以上、10以下 | | regex |regex("[bcm]at")| [bcm]atの正規表現に一致 | | integer | integer| 整数 | | float |float` | 小数 |
論理和(or)と論理積(and)も使えます。
- or:
is("Japan") or is("France")-> JapanまたはFrance。 - and:
length(2) and range(10,20)-> 長さが2の文字列かつ10以上、20以下。andを省略してもandと同様に扱われます。
その他にカッコでくくって論理のまとまりを作れます。
- parentheses:
(length(2) and range(10,20)) or empty-> (長さが2の文字列かつ10以上、20以下) または 空文字。
このようにすることで様々な条件を表現できます。
管理画面を想定したサンプルアプリを開く
table-validatorのレポジトリをcloneして以下のコマンドを実行すればDemoと同じReactアプリが動きます。
npm install && npm run react
example/react以下にサンプルのコードがあります。
システムのファイル連携を想定したサンプルCLIを実行する
以下でファイルを検証するCLIが実行できます。
npm install && npm run cli
以下は出力の一部です。
$ npm install && npm run cli
...
> cli@1.0.0 start
> npm run build && node dist/index.js ../../test-data/schema.yaml ../../test-data/data.csv
> cli@1.0.0 build
> tsc
ValidationRuleError: is("a") rule fails for value: "d", line: 2, column: 2
example/cli以下にサンプルのコードがあります。
どのような仕組みで実現しているか
もともとCSV Validatorというも のがありScalaで書かれています。 Digital Preservationという組織が連携相手からCSVを受け付けているときに検証するために作っているっぽいです。 CSV Schema Languageがその設定ファイルの定義をしています。
これが直接使えればよかったのですが、ブラウザで扱いにくい、このCSV Schema Languageが日本語のヘッダ名などを扱いにくいという問題があってじゃあちょっと作ってみようかなということで参考にして作ってみました。 ルールの部分はColumn Validation Expressionsを参考にしています。
table-validatorのスキーマのYAMLに書いてある(length(2) and range(10,20)) or emptyのようなルールはPEG(Parsing Expression Grammer)で構築しています。
バッカス・ナウア記法っぽく文法を定義することができます。
この記事を書いている時点でtable-validatorは以下の文法を持っています。
columnRule = columnValidationExpr*
columnValidationExpr = combinatorialExpr / nonCombinatorialExpr
combinatorialExpr = orExpr / andExpr
orExpr = left:nonCombinatorialExpr [ ]+ "or" [ ]+ right:columnValidationExpr { return { type: 'or', left: left, right: right } };
andExpr = left:nonCombinatorialExpr andOrWhiteSpaceLiteral right:columnValidationExpr { return { type: 'and', left: left, right: right } };
andOrWhiteSpaceLiteral = [ ]+ "and" [ ]+ / [ ]+
nonCombinatorialExpr = nonConditionalExpr
nonConditionalExpr = singleExpr / parenthesizedExpr
singleExpr = notEmptyExpr / emptyExpr / isExpr / notExpr / uniqueExpr / rangeExpr / lengthExpr / regExpExpr / integerExpr / floatExpr / anyExpr
notEmptyExpr = "notEmpty" { return { type: 'notEmpty', text: text() }; }
emptyExpr = "empty" { return { type: 'empty', text: text() }; }
isExpr = "is(" _ value:stringProvider _ ")" { return { type: 'is', value: value, text: text() }; }
notExpr = "not(" _ value:stringProvider _ ")" { return { type: 'not', value: value, text: text() }; }
uniqueExpr = "unique" { return { type: 'unique', text: text() }; }
rangeExpr = "range(" _ min:integerLiteralOrAny _ "," _ max:integerLiteralOrAny _ ")" { return { type: 'range', min: min, max: max, text: text() };}
lengthExpr = "length(" _ min:(value:positiveIntegerOrAny _ "," { return value; })? _ max:positiveIntegerOrAny _ ")" { return { type: 'length', min: min, max: max, text: text() }; }
regExpExpr = "regex(" _ value:stringLiteral _ ")" { return { type: 'regex', value: value, text: text() }; }
integerExpr = "integer" { return { type: 'integer', text: text() }; }
floatExpr = "float" { return { type: 'float', text: text() }; }
anyExpr = "any(" _ leftValue:stringProvider _ rightValues:("," _ value:stringProvider _ { return value; } )* ")" { return { type: 'any', left: leftValue, right: rightValues, text: text() }; }
stringProvider = stringLiteral
stringLiteral = '"' value:[^"]* '"' { return value.join(""); } // any character except '"'
positiveIntegerLiteral = value:[0-9]+ { return parseInt(value.join(""), 10); }
integerLiteral = "-"?[0-9]+ { return parseInt(text(), 10); }
wildcardLiteral = "*"
positiveIntegerOrAny = positiveIntegerLiteral / wildcardLiteral
integerLiteralOrAny = integerLiteral / wildcardLiteral
parenthesizedExpr = "(" _ values:columnValidationExpr+ _ ")" { return { type: 'parentheses', values: values }; }
_ "whitespace" = [ ]*
上記をパースするためにpeggyというnpmパッケージがあります。peggyで上記のスキーマよ読み込んでから(length(2) and range(10,20)) or emptyを解析するとAST(Abstract Syntax Tree)を出力できます。
ただ、ASTをパッケージ内で使うために再度Typescriptの型にしなければらないので面倒でした。そこでts-pegjsがあり、このパッケージはPEGを読み込みTypescriptの型を作ってくれます。
なんだかプログラミング言語を作っているようで楽しいです。
スキーマのYAMLファイルをパースできて設定が読み込めたらあとは順番にCSVを検証していくだけです。
まだ足りていないところ
作ったばかりなのでいっぱい足りないところがあります。
- csvをstreamで読むようにする
- dateを実装する(11/31みたいに不可能な文字列を入れれないようにする)
- ヘッダ名をチェックする
- 他の列も参照できるようにする
- Shift JIS対応する
- npm install -g table-validatorでtable-validatorのCLIコマンドを実行できるようにする
- Electronをビルドしてアプリにする
- CIを整える
- CSVの検証の速度を上げる(Rustとかで書いたほうがいいのかも)
年末年始のあいた時間でいろいろ対応していこうと思います。
まとめ
各所でSWEを困らせているCSVの検証するパッケージのtable-validatorを作りました。ちょこちょこ育てていこうと思います。