AWS Glueのデータ品質定義言語(DQDL)で外部連携で送信されるファイルを連携元が自律的に検証できるようにする
システムを開発していると外部からファイルを受け取り利用することがあります。 たとえば、ネットスーパーを開発していると、小売企業から店舗・カテゴリ・商品などのファイルを受け取りそれをもとにネットスーパーの売り場を作ります。
この外部連携ファイルというのは結構くせもので以下のような事がたびたびあります。
- ファイルが送られてこない
- ファイルが送られてきたが空だった
- 特定のカラムはユニークな値しか入っていないはずが重複している値がはいっていた
- 整数で来るはずが少数になっている
- 値がはいっているはずなのに空文字しか入っていない
- 値が特定の値に収まっていない
ようするに想定されているファイルが来ていない、つまり制約(データコントラクト的なもの)に違反しています。
そもそも最初に連携元と制約を定めておけばいいのでは?となるのですが連携時は大量のファイル形式があり、そのファイルのどのカラムを使って、カラムにはどのような性質があったり、先方も詳しくないデータがあったります。 実際の業務では、ファイルをいただいてそのファイルの中身を確認して各種制約を確認して。その後エラーがあったときに制約を追加したりします。 往々にしてこの制約を破っているファイルは送信先が取り込み時や取り込んだあとに気づく事になり制約を破っていますというのを連携元に伝えるコストが大きいです。連携元も制約に違反しているか定期的に確認していなかったりします。
この記事では、このようなファイルが正しくないという不毛なやり取りを減らすため、AWS Glueを使って解決する手順を示します。
要望
先ほど外部連携の実態を述べましたがまとめると以下のような要望がありこれの解決をAWS Glueで行っていきます。
- 外部連携ファイルが正しいかどうかの制約を開発者でなくても簡単に定義でき確認できる
- 外部連携ファイルの送信側がエラーに気づいて自律的に修正できる
- 未検証のファイルと検証済みのファイルは区別したい
前知識
データ品質定義言語 (DQDL)はAWS Glueで使えるデータの制約を制約定義する言語です。 以下のようにかけます。
Rules = [
IsComplete "order-id",
IsUnique "order-id"
]
これを定義すると、Glue上でDeequがデータがその制約を満たしてくれているかチェックしてくれます。 DeequではScalaなどのコードで書かなければいけないところをDQDLは比較的開発者でなくてもわかる構文となっているので要望の1を満たすことができます。 制約は常に更新されるので開発者でなくても定義できるのは大事です。
システム概要
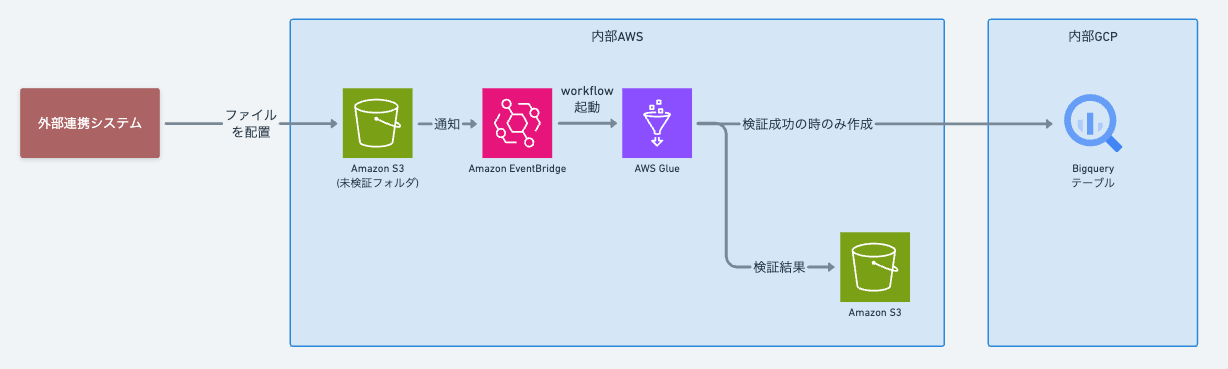 システム構成図
システム構成図
上記がシステム構成図です。
外部連携システムからS3にファイルが配置されるとEventBridgeにイベントが送信されます。 そのイベントをもとにAWS Glueのワークフローを起動し、ファイルに対して「データ品質定義言語 (DQDL)」で定義した制約定義を検証します。
制約の検証結果はS3に保存します。 データがすべての制約を満たしていればBigQueryのテーブルを作成します。
上記により、要望の2と3を満たすことができます。 外部連携の企業は検証結果のファイル(JSON)にアクセスできるので検証結果にエラーがあるかどうか確認して、あれば修正して再度アップロードします。 ファイルを置くだけでなくそのファイルが制約を満たしているかどうか確認するまでが外部連携企業の責務です。
もし検証結果のファイルが読み込めないと企業が伝えてきた場合は、ファイルが置かれたらJSONを読み込み処理を行い、エラーがあれば先方に通知するといいでしょう。
BigQueryにテーブルがあればそれは検証済みのデータという事です。このAWS Glueが腐敗防止層の役割を果たしてくれるのです。
実際の設定例
それではシステム概要通りにAWSに構築していきます。
S3の設定
バケットを作り以下のようにEventBridgeにイベントを送るように設定します。この設定変更は5分程度かかります。
(今回、バケットの名前はwapa5pow-blog-testという名前にします)
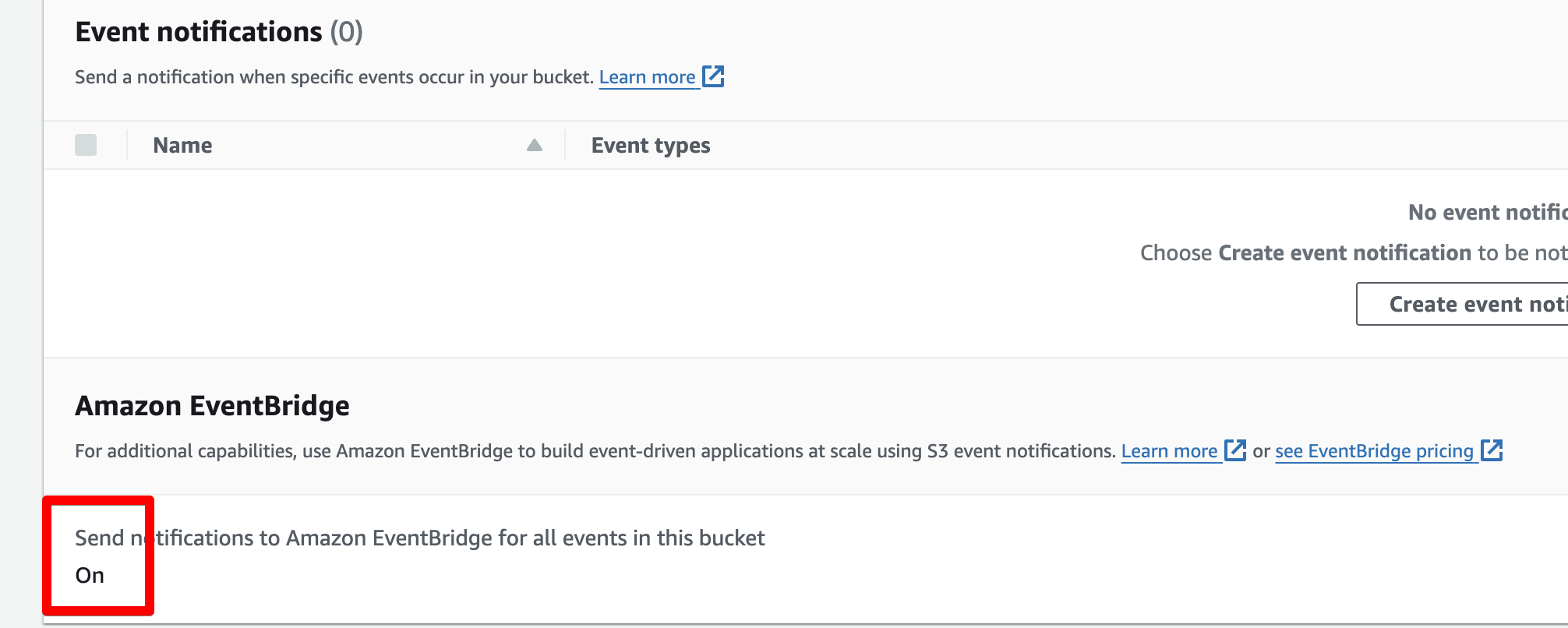 バケットの設定
バケットの設定
またバケットにはcust.csvというファイルをアップロードしておきます。
GlueのETL job設定
最初に以下のようにVisual ETCで設定し、process_custという名前にします。
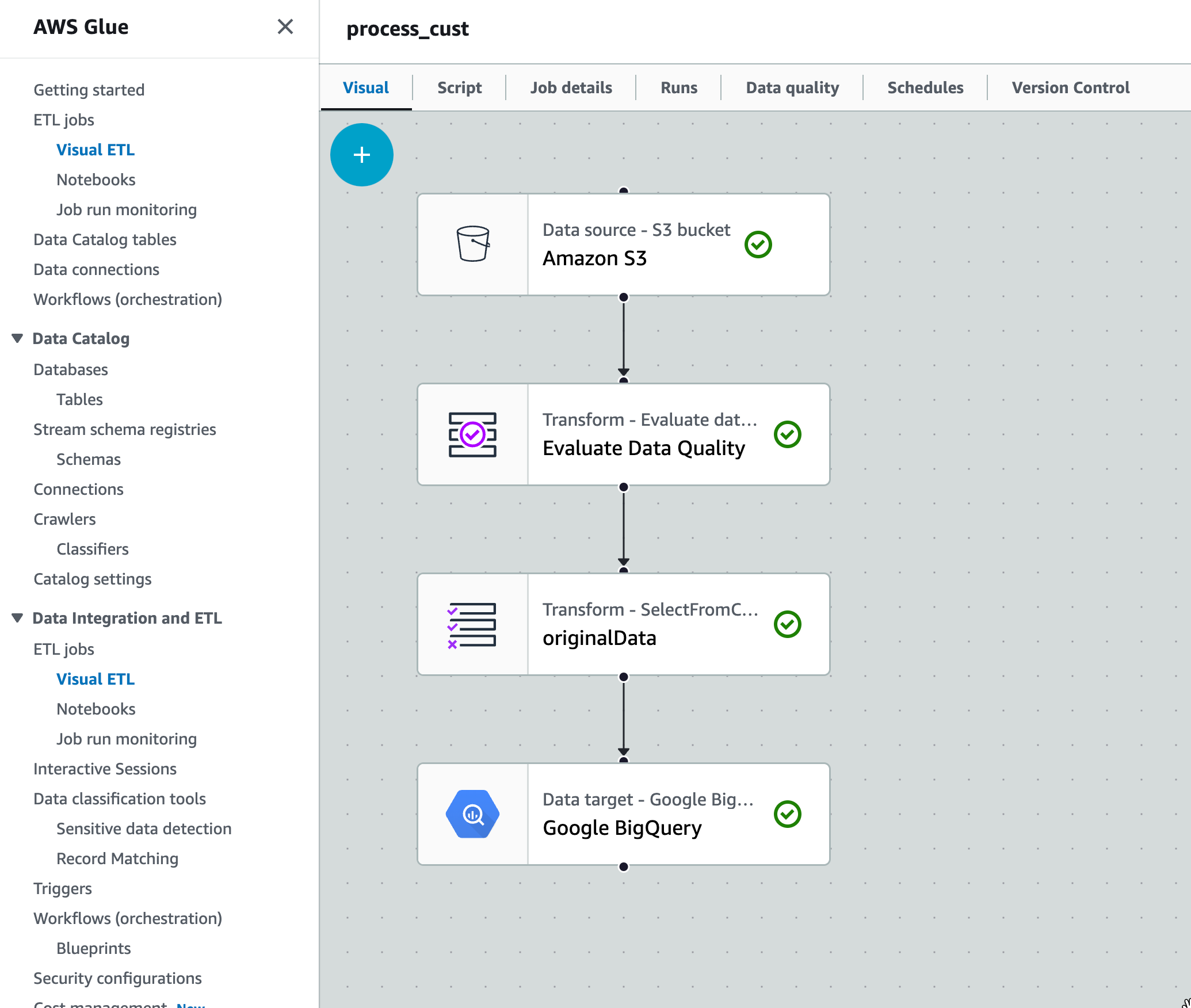
各ブロックの中身を見ていきます。
Amazon S3の設定
特定のバケットのファイルを読み込みます。
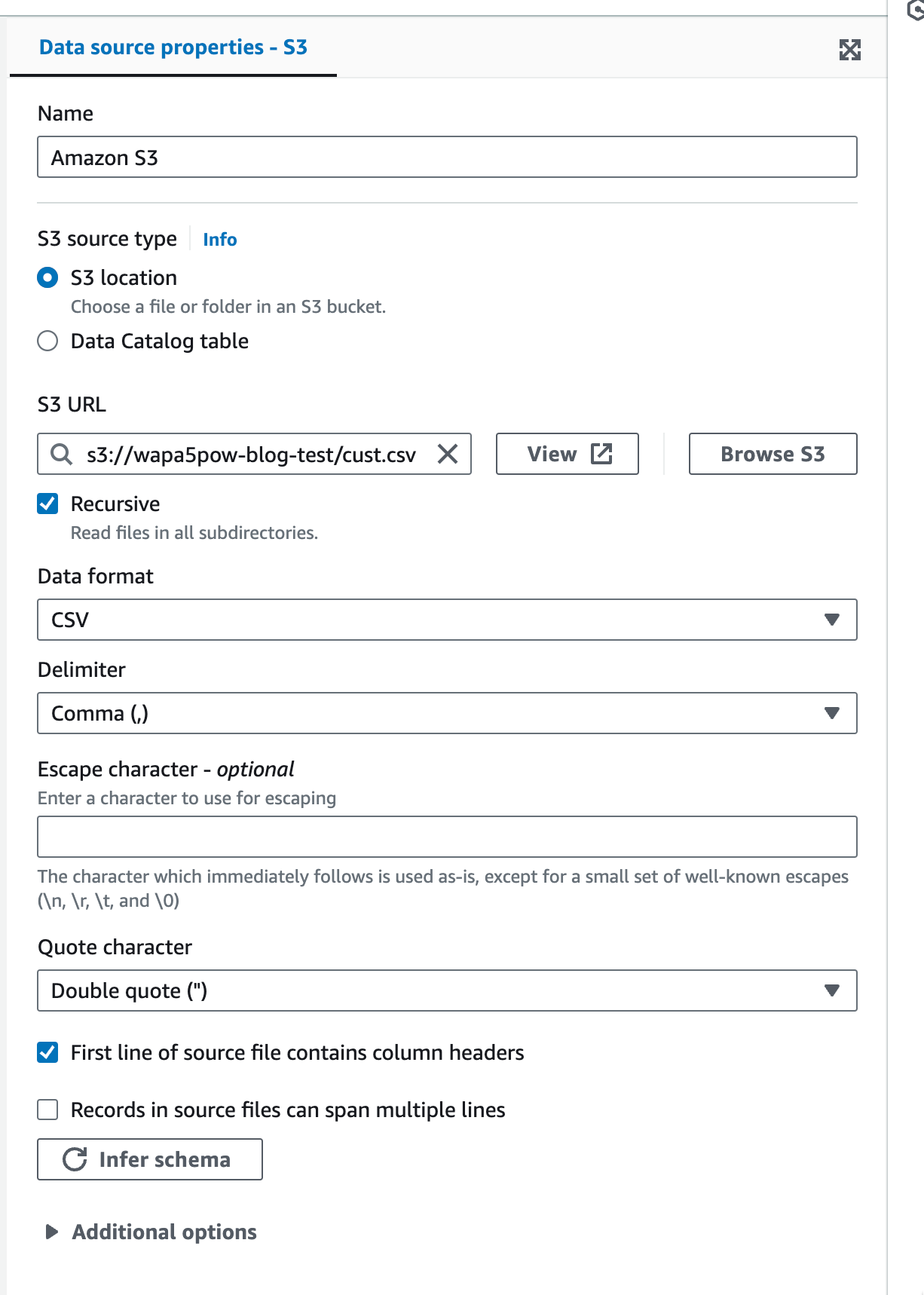
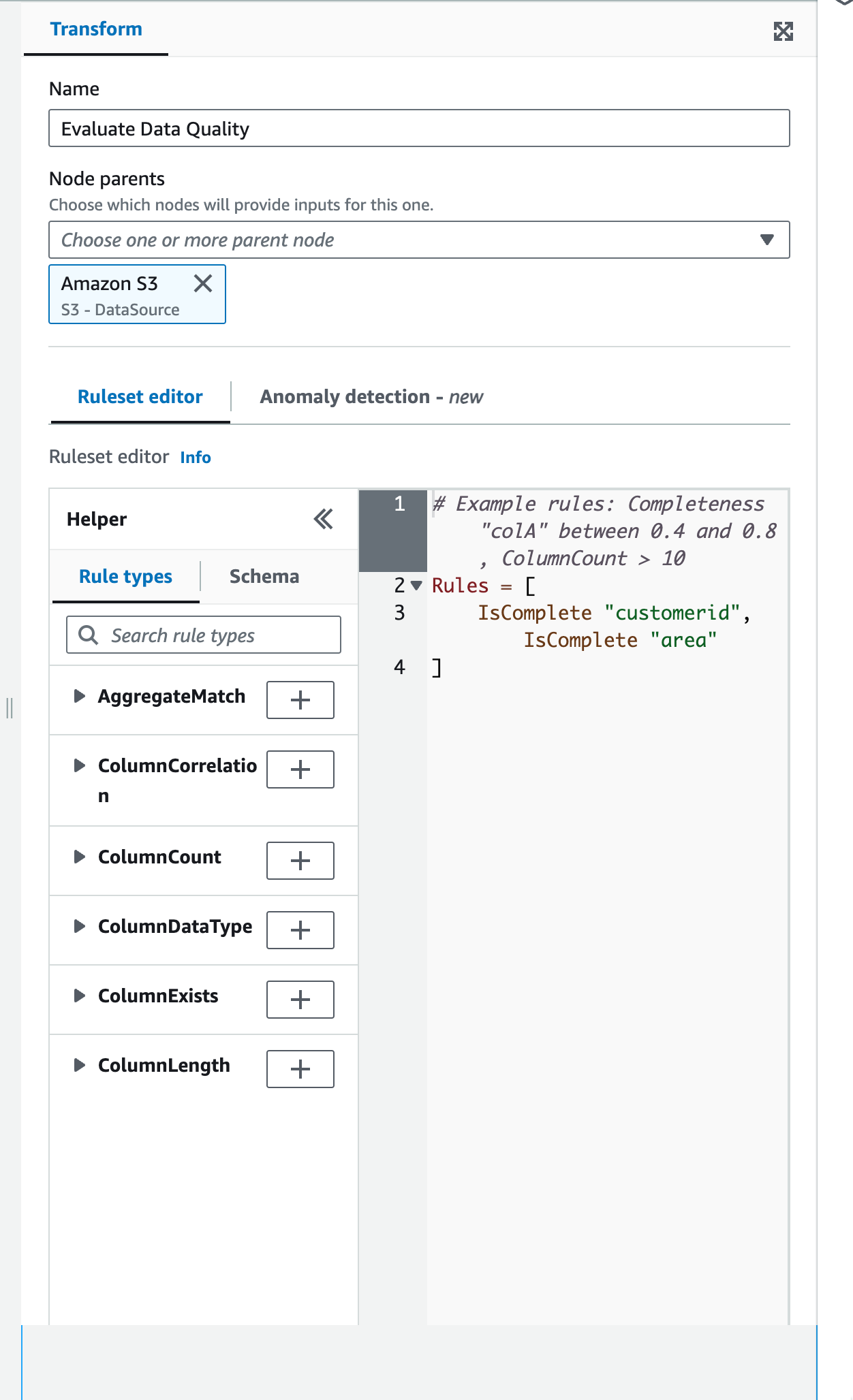
Evaluate Data Qualityの設定
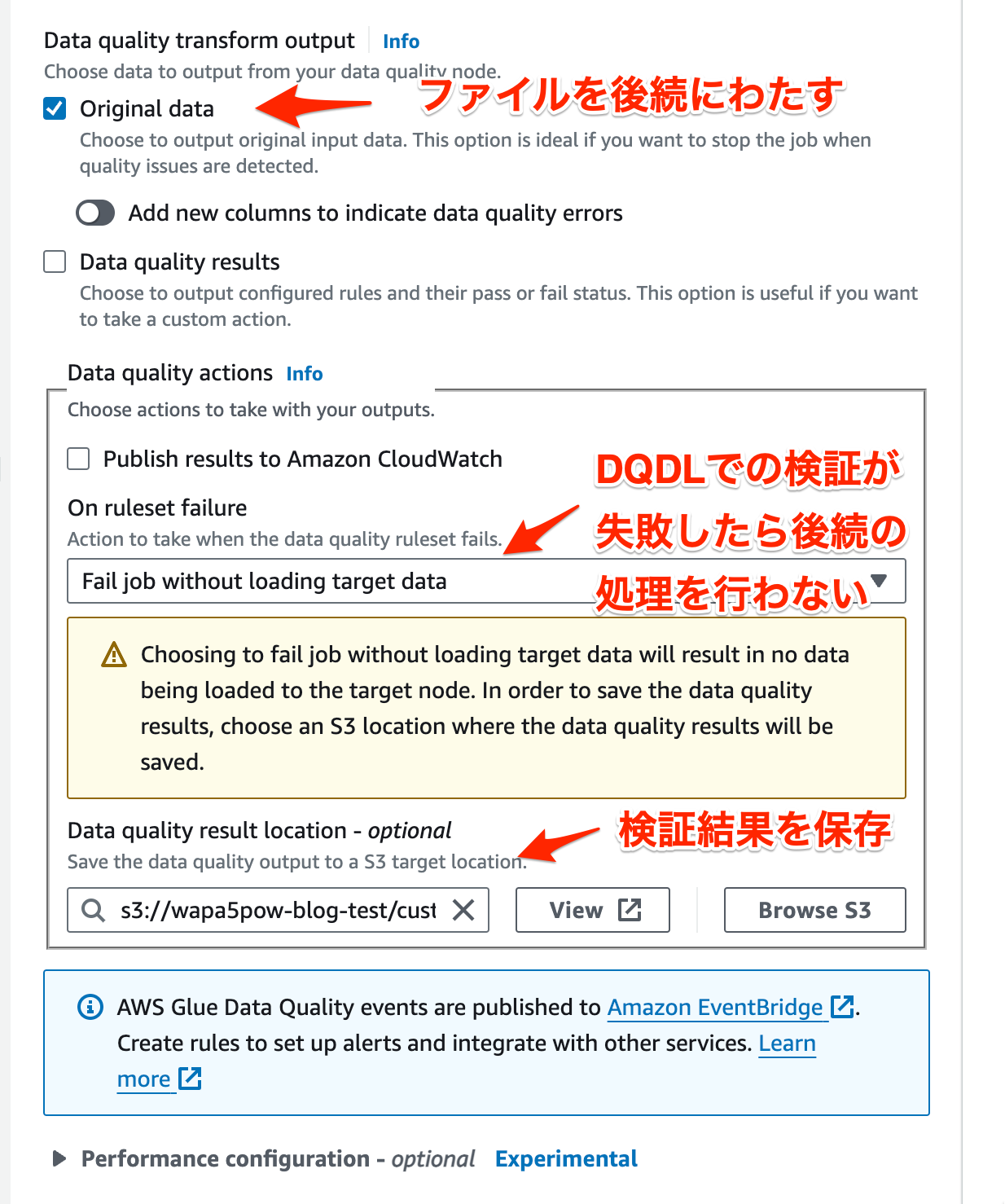
ファイルの検証をDQDLで行います。 以下の設定を行う事で成功したときのみ後続の処理(今回はBigQueryへのテーブル作成)を行えます。
Google BigQueryの設定
BigQueryへファイルをテーブルに変換して保存します。スキーマは自動で定義してくれます。 BigQueryへのアクセス権のあるサービスアカウントを、AWSのシークレットとして作成してアクセスさせます(参考)。
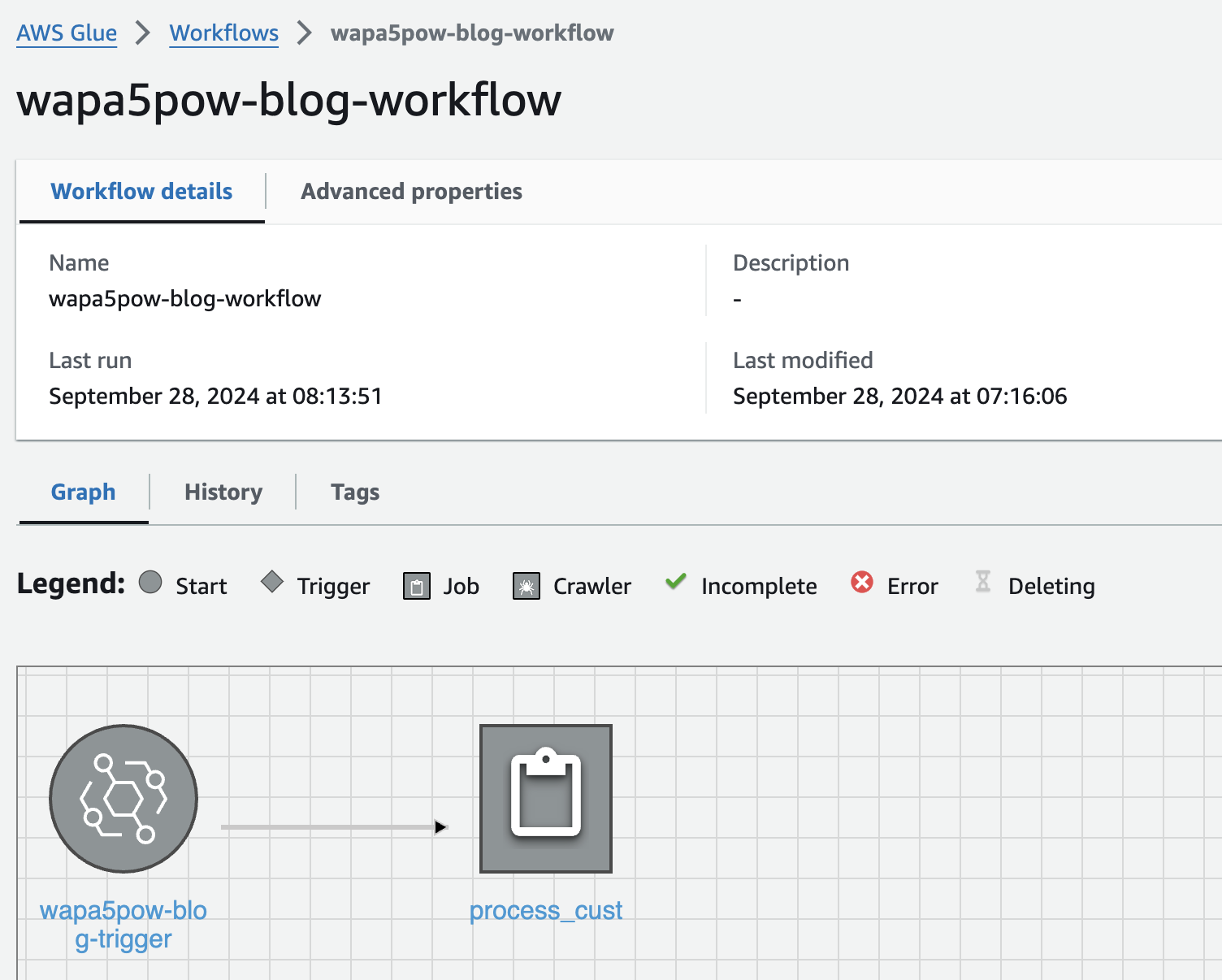
GlueのWorkflow設定
ETL jobをEvent Bridgeから呼び出せるようにするためにはGlueのWorkflowを作る必要があります。 以下のように作っておきます。
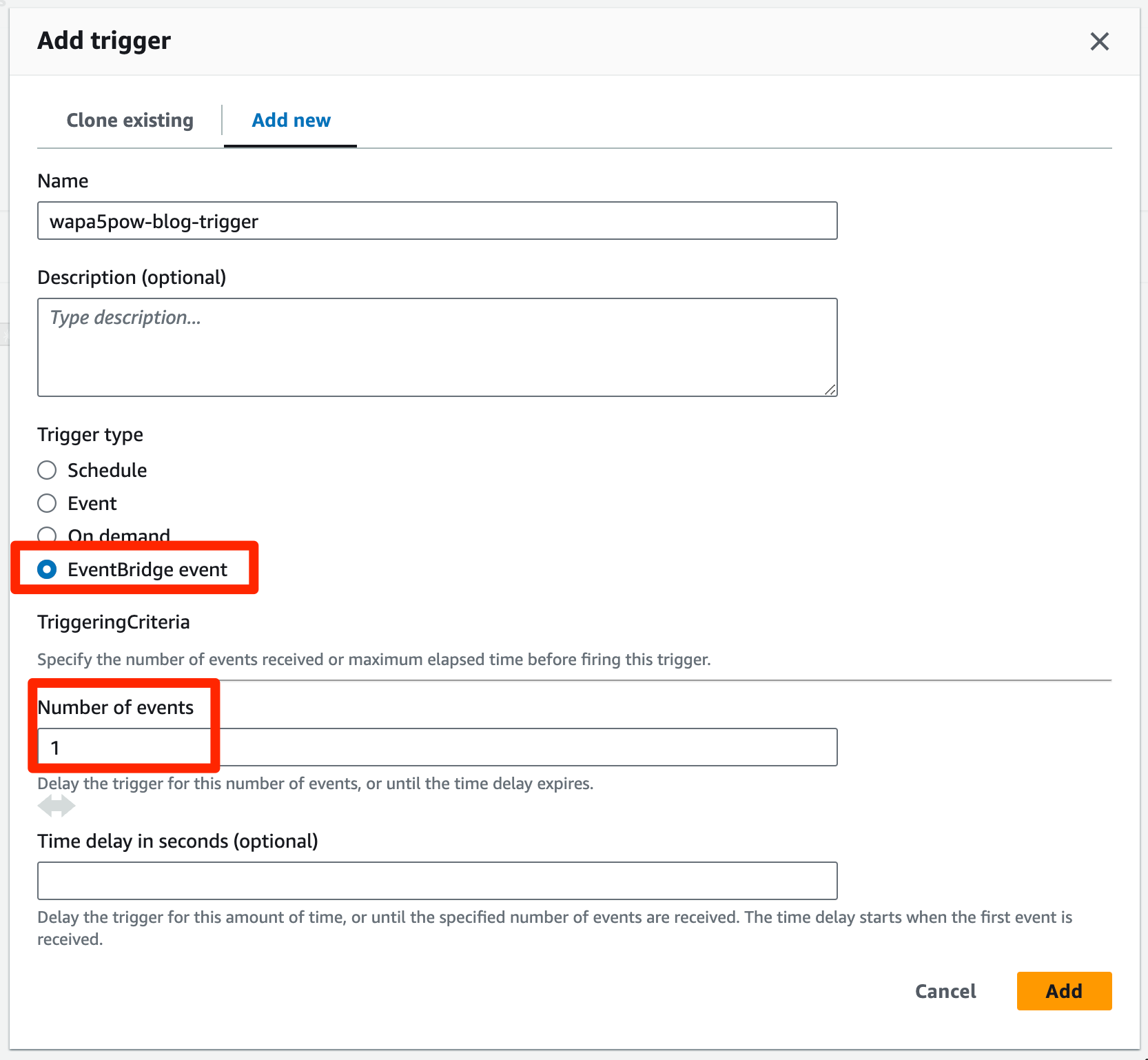
Workflowの中でトリガーを追加します。
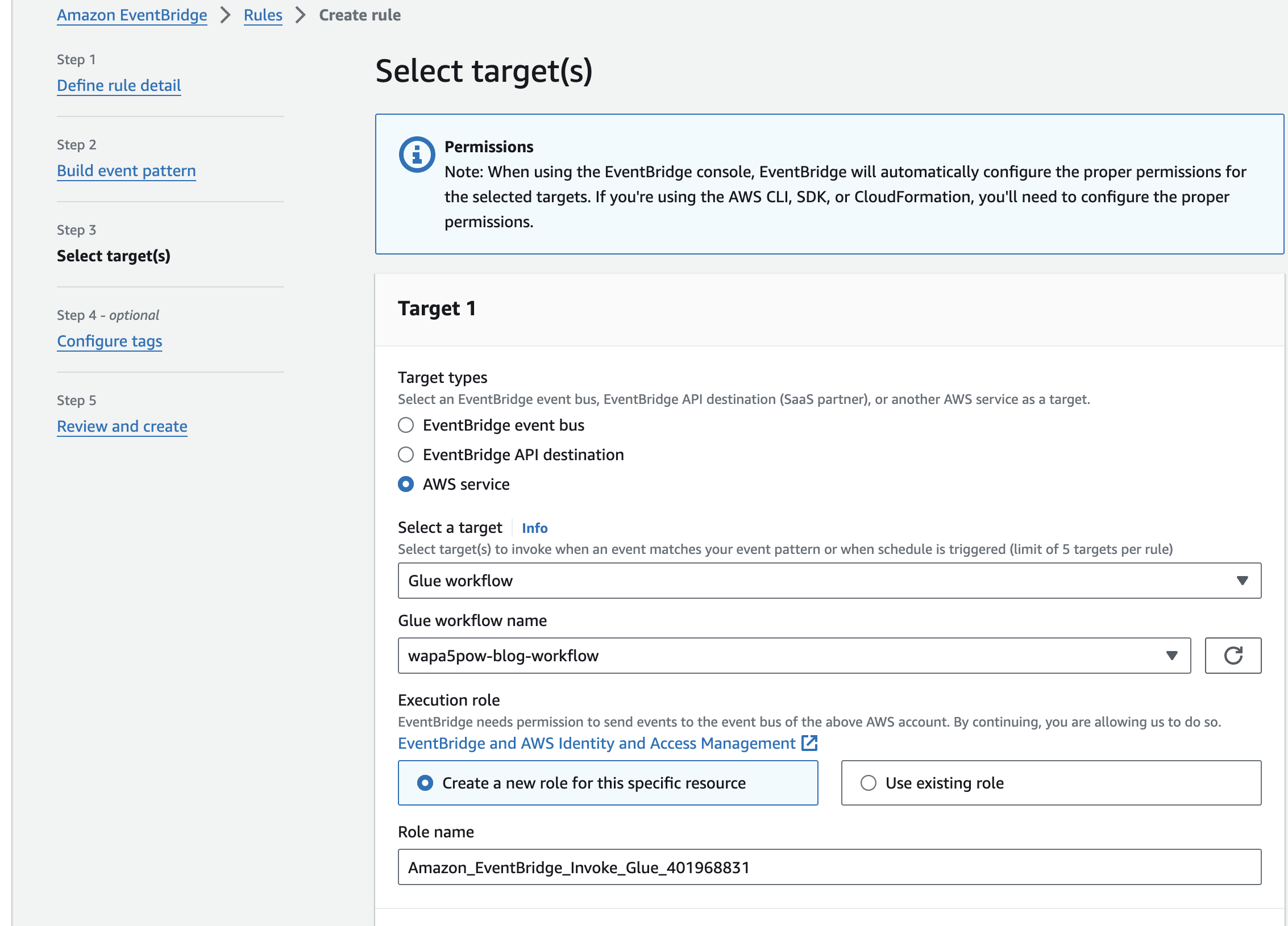
EventBridgeの設定
最後にEventBridgeの設定を行います。
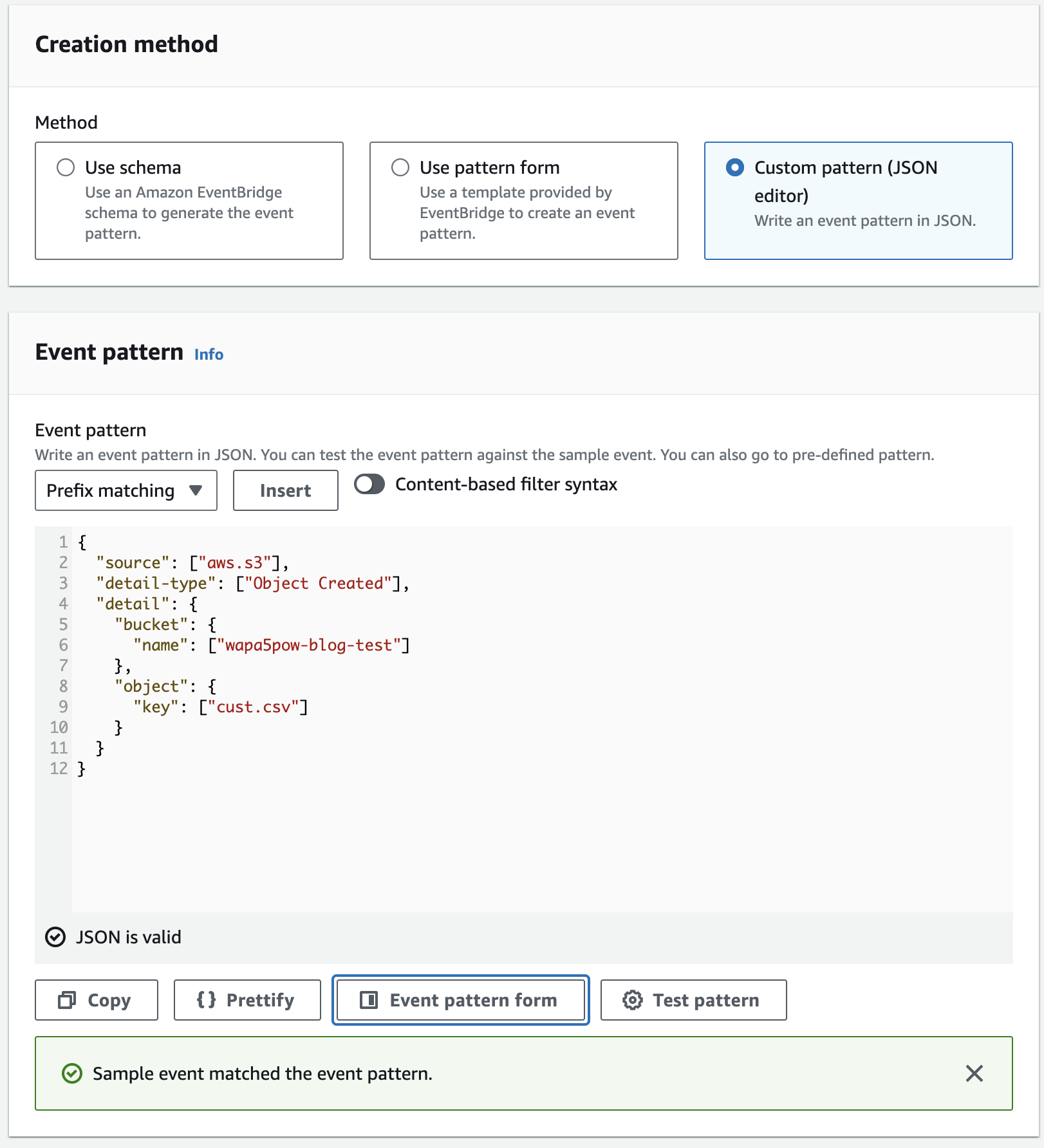
以下の設定でcust.csvだけ反応するようにします。S3のObject Createdのイベント構造はこちらを参考にしてください。
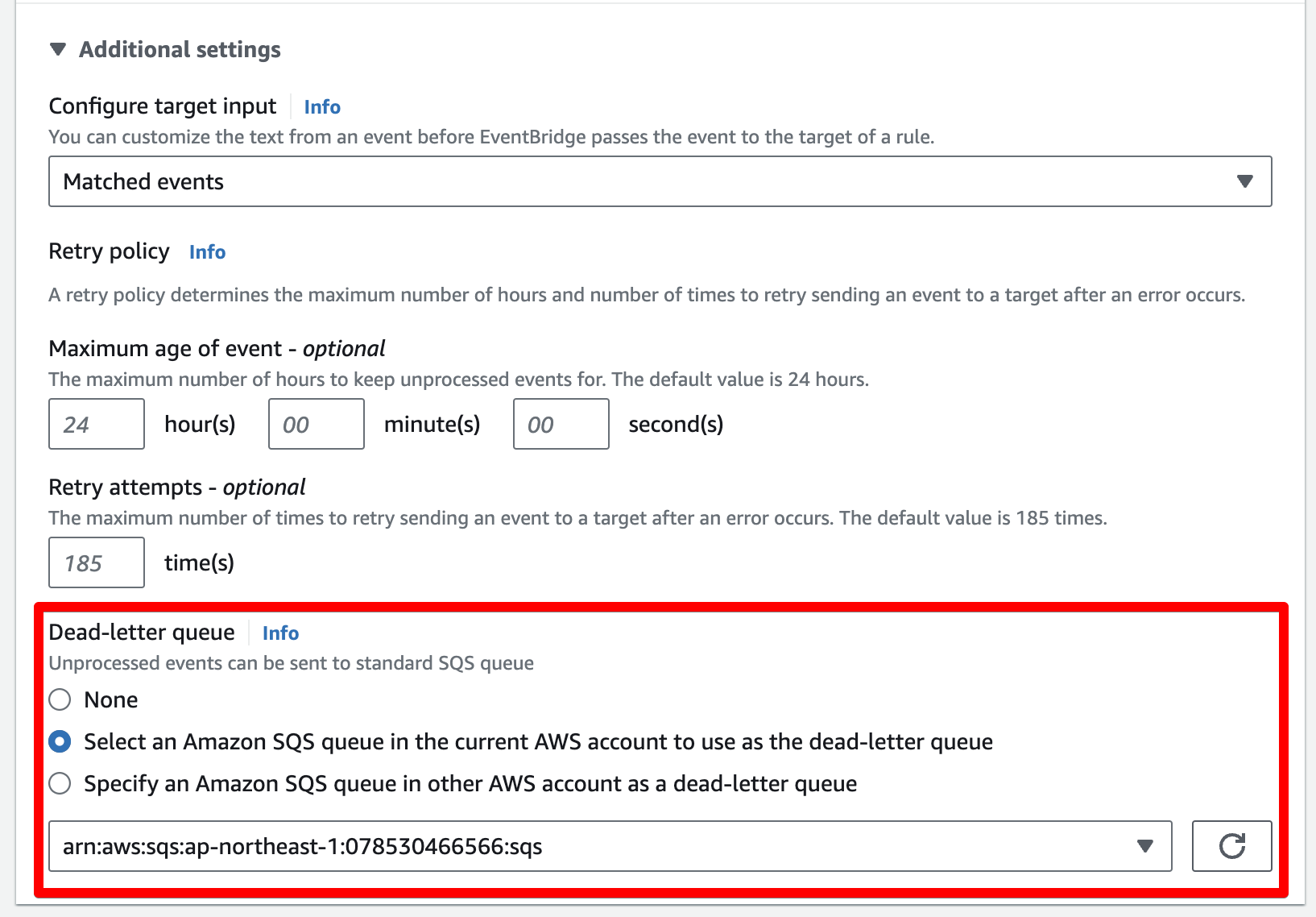
以下のように、Additional settingsのDead-letter queueを設定することで、EventBridgeでエラーがおきたときにエラーログを送る事ができます。 EventBridgeのエラーの確認は面倒なので設定しておくとよいでしょう。
まとめ
外部連携の企業からS3にファイルが置かれたらそのファイルを検証して、制約を満たしていればBigQueryのテーブルを作るというシステム構成が作れました。 ファイルが増えたらいちいち作る必要がありますが、同じような設定なのでTerraformで設定するといいかもしれません。 Terraformにすると開発者しかさわりにくくなるので、最初だけTerraformにするかとか悩みどころです。
最近は、データ検証系のサービスはいくつも出てきているのですが基本Glueと同じ事ができると思います。 ただ各社使い勝手が違うので実際にやりたいことを検証しながらサービスを選定するといいと思います。
動作確認
それではs3://wapa5pow-blog-test/cust.csvにファイルを配置して動作を確認してみます。
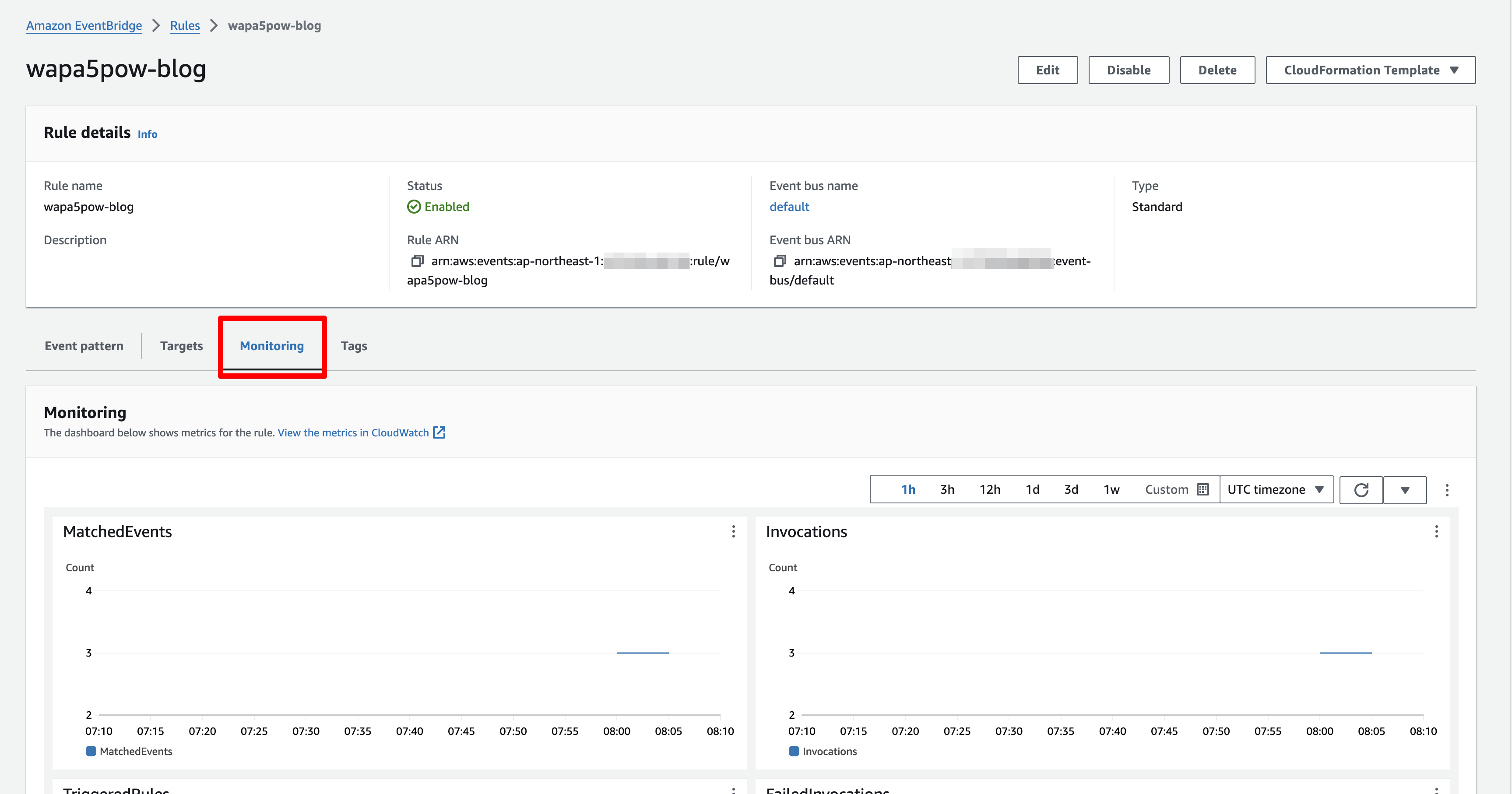
うまく動作していればEventBridgeにイベントが送られ、Monitoringで確認できます。
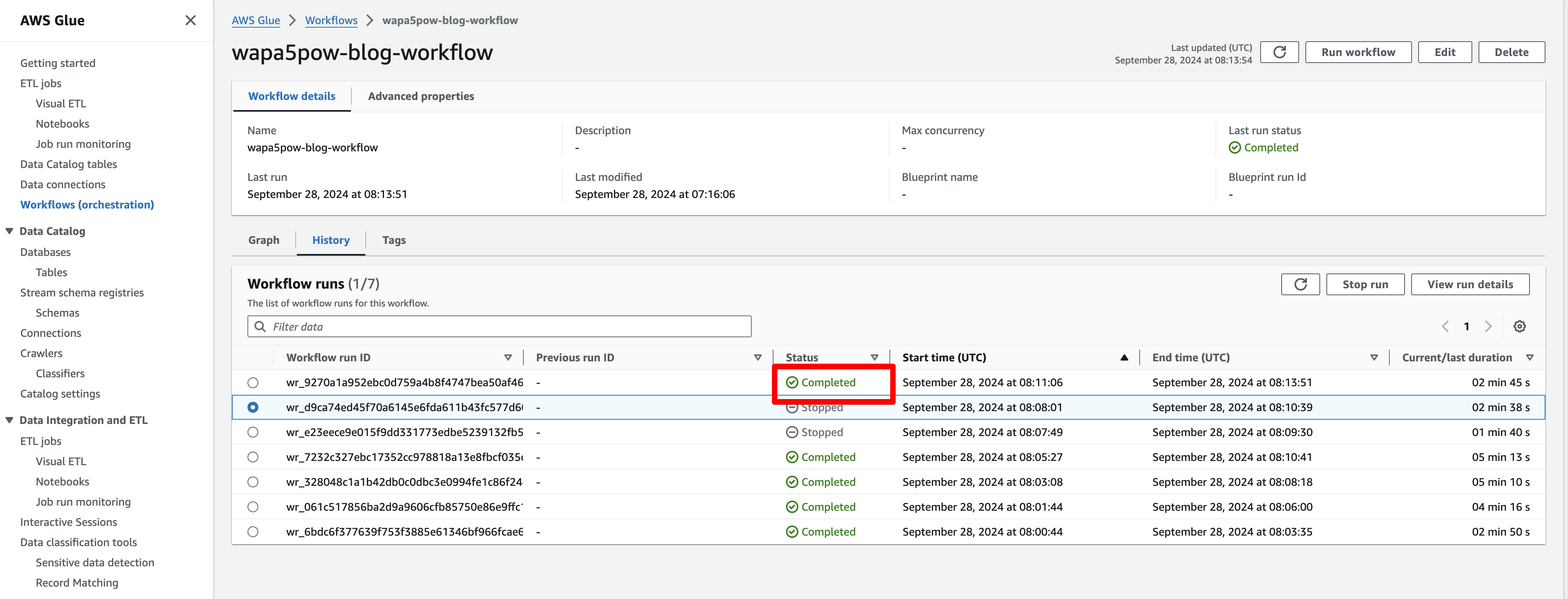
GlueのWorkflowが正しく動いているかHisotryから見て、Completedになっていれば正しく動いています。実際にBigQueryのテーブルが作られている事を確認しました。
参考
参考資料です
各種調べていて見つけた制約を守らせる他の手段も書いておきます。
- Google CloudではDataplexを使って品質を定義できます
- Microsoft Purviewでもできそうですが詳しくはさわってません
- Torocco データチェックではBigQueryのテーブルが正しいか検証できるよう
- DQOpsではブラウザ上で各種品質を定義できたりします。SaaS + OSSという感じでした
- Data Contract CLIはCLIでスキーマをチェックできます。