書籍「大規模データ管理」を読んで考える、開発者もデータ利用者も幸せなアーキテクチャ
オライリーから出ている「大規模データ管理 第2版」を読んで、開発者だけでなくデータ利用者(データを分析したり外部パートナーにデータを提供したりとプロダクトで生成されるデータを利用する役割を想定)も幸せなアーキテクチャを考えるきっかけになりました。 (ちなみに第1版を積読していて読んでみたらなんと2版も最近でていて両方読みました。第2版は第1版に比べてかかれている内容が結構違ってどっちも楽しめました。第2版のほうがAzureを使った実現方法まで踏み込んで書いてありました。)
書籍内では、Scaled Architectureとして、ドメインベースの参照アーキテクチャを示しています。これには設計、原則、モデル、ベストプラクティスなどが含まれていて示唆に富む内容でした。
いままで各種システムを開発してきた中で、開発者としての自身ではデータベースのスキーマを設計したりBigQueryにデータを入れて使いやすくしていたりしてデータ利用者の事はやや考慮していました。データ利用者はBigQueryのテーブルのスキーマからデータを推定したり都度開発者に聞いたりして外部提供用の分析結果などを作っていました。 ある程度はこれで回るのですが、開発者ファーストでデータ利用者はそれを利用するだけという形ですすめるとだんだん以下のような問題がでてきます。
- データ利用者が目的の分析を行うためにどのテーブルのどのフィールドを使ったらいいかわからない
- データ利用者が必要なイベントのデータがデータベースに存在しない。改修もどこに依頼したらいいかわからない。
- 開発者がテーブルをマイグレーションして、データ利用者が気づいたらスキーマが変わっている
- BigQueryがデータベースと同期していないときがあるが、特にSLAを定義しているわけではないので責任の所在が曖昧
開発者もデータ利用者も幸せなアーキテクチャの例
前述の問題に関して書籍を参考に、アーキテクチャを考えてみました。 複数のドメインがありそれぞれドメイン間でデータ連携することを想定しています。外部システムからデータを取り込む例も書いていますが、外部システムに公開するAPIやWebhookはここでは記載の対象としていないです。
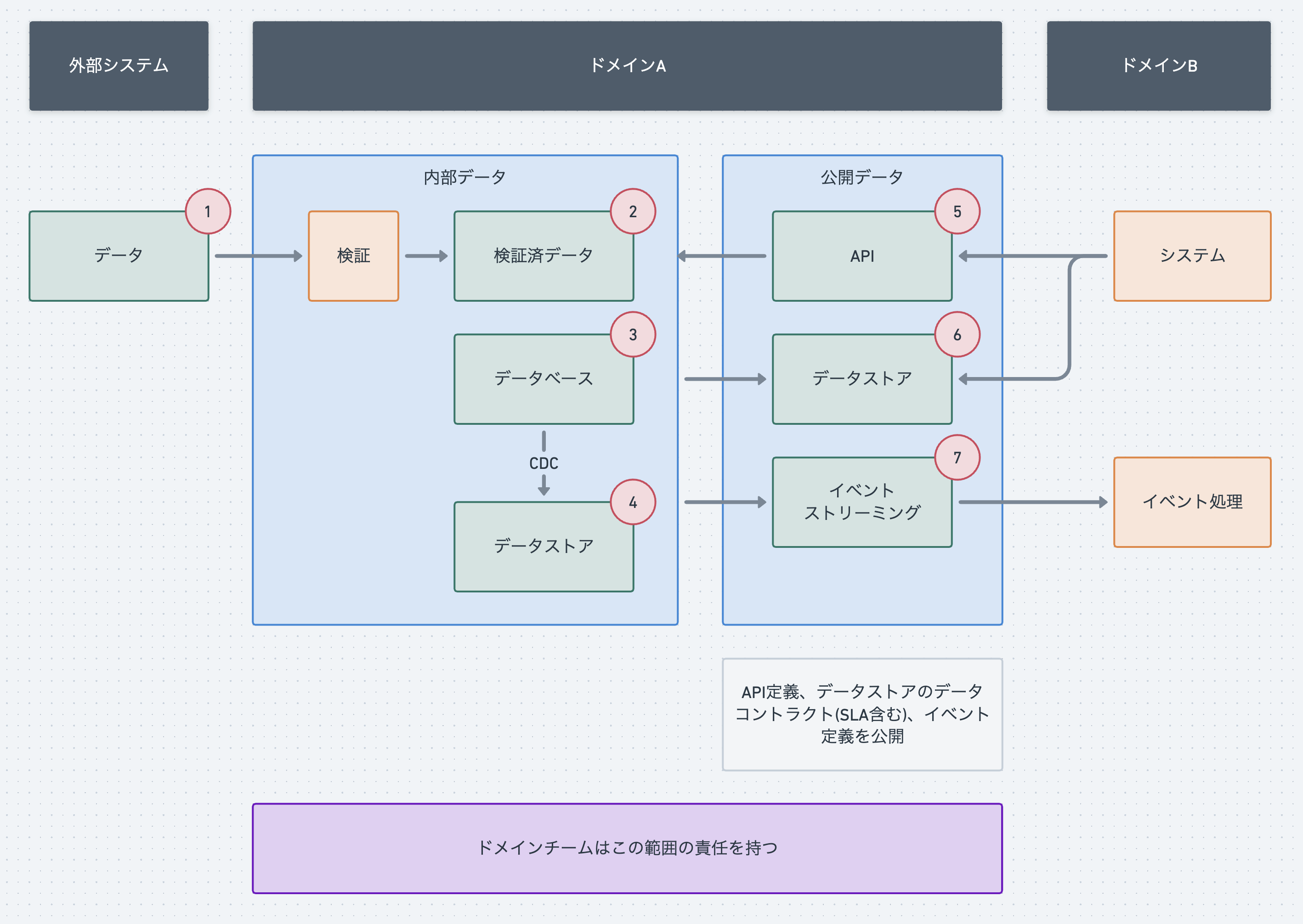
ドメインAの内部では内部データと公開データに分けます。ドメインチームはどちらのデータに対しても責任を持ちます。
内部データ
内部データは別ドメインや外部から参照されない隔離された場所に保存します。
1のデータは、外部から取得したり配置されたりするデータで、検証を経て完全性のあるデータとして2の検証済みデータとなります。このデータをドメイン内のシステムで利用すれば外部データに不正なデータが含まれていたり欠損してたりということに悩まされなくなります。
3のデータベースは、内部でのみ使うものなのでPostgreSQLなどドメイン内で適切なものを選べます。4のデータストアへCDC(Change Data Capture)で、ほぼリアルタイムにデータを更新します。
4のデータストアは、BigQueryなどスケーラブルなデータベースを選ぶと良いでしょう。データサイエティストなどデータ利用者はこのデータベースにクエリすることができます。ただしアドホックなクエリでの利用を想定していてビジネスパートナーなどへの分析結果を定常的に取得する目的では使わないです。スキーマもデータベースをマイグレーションすれば変わり得ます。
公開データ
公開データは別ドメインから利用されるデータです。公開されるものなので合意のない破壊的変更は行えません。
5のAPIは、別ドメインからリアルタイムでドメイン内のデータを取得したり更新したりする目的で使われます。OpenAPIなどの定義書でバージョン管理やリクエスト・レスポンスの型の定義を行い、SLAも設定します。
6のデータストアは、ほぼリアルタイムのデータを別ドメインが利用したり分析に利用されたりします。データコントラクトを定め利用者側のニーズに応じてSLAを設定します。このデータストアは別ドメインが使うであろうデータを定義したものなのですべてのテーブルを公開するというかは別ドメインで必要となりそうなモデルを定義して絞り込んで公開するイメージです。頻繁に更新されるのを防ぐためある程度汎用的にモデルを作るのがよいでしょう。6のデータストアはドメイン内部の多くのデータを公開しているわけではないのでアドホックな分析には4のデータストアを使い、定常的に使いたくなったらドメインの開発者に6を提供してもらうイメージです。
7のイベントストリーミングは、注文購入などのイベントを別ドメインでサブスクライブするために設定されます。こちらもイベント定義を設定し何日後にイベントが期限切れになるかなど明確にします。
まとめ
開発者もデータ利用者も幸せになるアーキテクチャを作成してみました。昨今ますます開発者以外がデータを使う事が増えています。 アーキテクチャは最初に意識しておかないと途中で変更するのは骨がおれるので今後開発するときは開発者・データ利用者両者の視点で必要なものを実装できるとよさそうです。
全部BigQueryに放り込んでおくのは楽なのですが、公開されるものという事を考える事でデータへの理解を深めより安全なシステムを作る事ができます。