理想のデータ基盤に刷新する
株式会社スタイルポートでデータ基盤を刷新した方法を紹介します。最終的に出来上がったものは以下のようになりました。
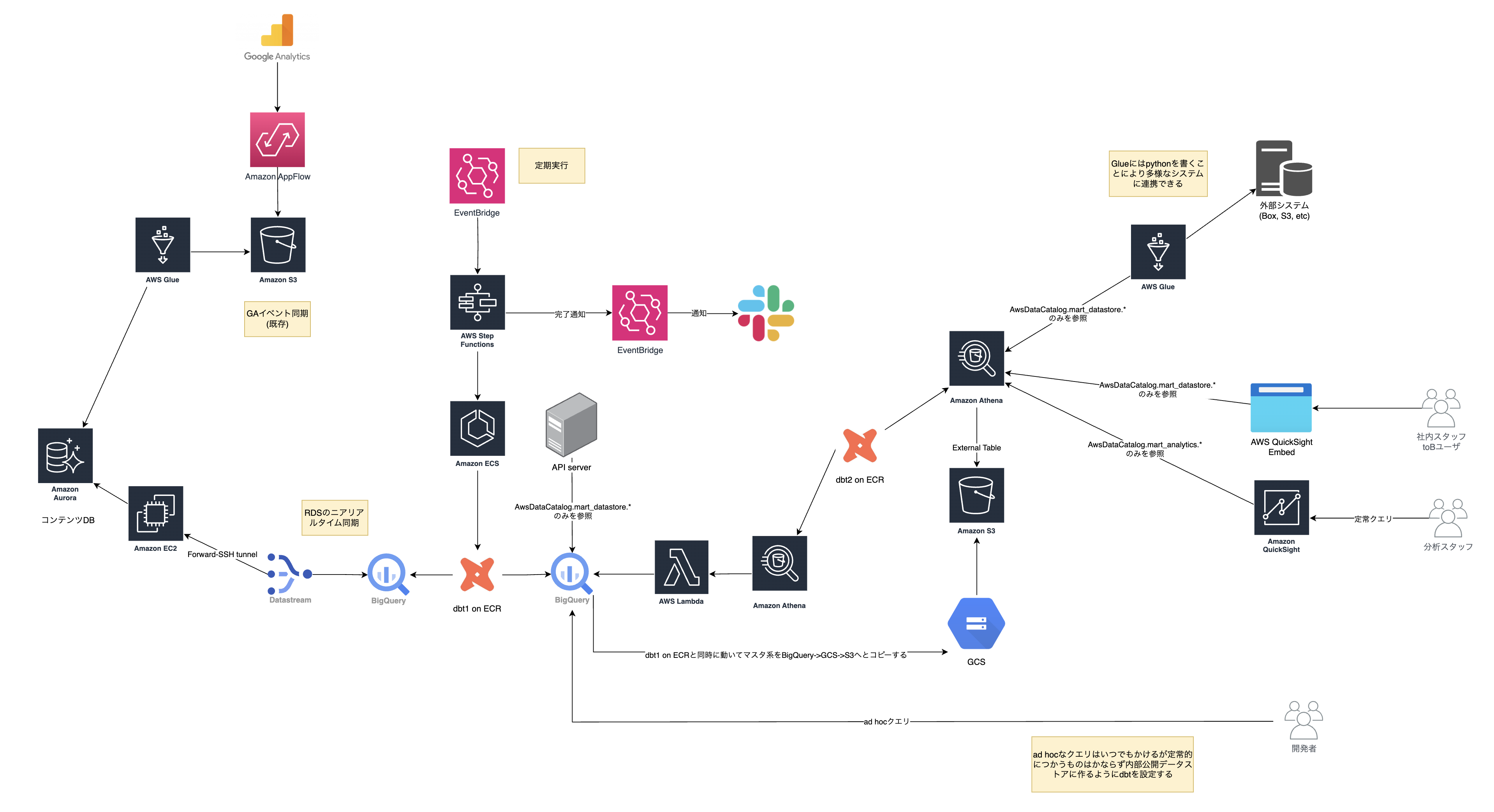
検討〜リリースまでを3ヶ月ほどで行いました。理想のデータ基盤を定義してから、実装する上で様々な制約が見つかったので、最初の設計時と実装に差分があります。各社、各プロジェクトで状況があると思いますので、なぜ最初と変更したかも読んでくださる方の今後の参考になればと思います。
それでは目次からです。
目次
開発全体の流れ
開発全体の流れは以下です。
- 要求分析
- 現状分析
- 理想のデータ基盤設計
- 現実のデータ基盤実装
要求分析
関係各所とコミュニケーションを取り、データ基盤を更新することにより実現したいことをまとめました。リアルタイムで分析したいという要求がないので、ニアリアルタイム同期は必要ない、など要求の内容が実装に影響します。実装の制約により要求自体を変えるのは問題ないですが、あらかじめ明らかにしておくことにより関係各所で意思疎通が取れます。
must-haveとして明らかになった要求は以下です。
- QuickSightでKPIモニタリングができる。既存のQuickSightのグラフが再現できる。
- TableauなどのBIツールと接続できる。
- SQLを用いたアドホックな分析ができる。
- 他グループやお客様のためにCSVが出力できる。3rd Partyへデータ提供ができる。
- AIの学習データとして利用できる。
- 集計クエリがソースコード管理されている。
- アドホック分析ではだれがいつどのようなクエリを発行したのかの証跡ログを残せる。
- 既存の特定時点以降の既存データが入っており、新しいデータ基盤でも過去の分析ができる。
- ダウンタイムを極力不要とする。
- データ基盤でログのロストがなかったりメンテナンスの少ない堅牢なアーキテクチャにする。
- 本番のテーブルが増えたりカラムが増えたりしても少量の開発で対応できる。
- コストが抑えられている。
細かいところは他にもありますが上記を満たすように設計をしていきます。
現状分析
次に既存システムの現状分析を行います。まず全体を把握して、どこを置き換えてどこを残すかのトレードオフを検討する基礎になります。
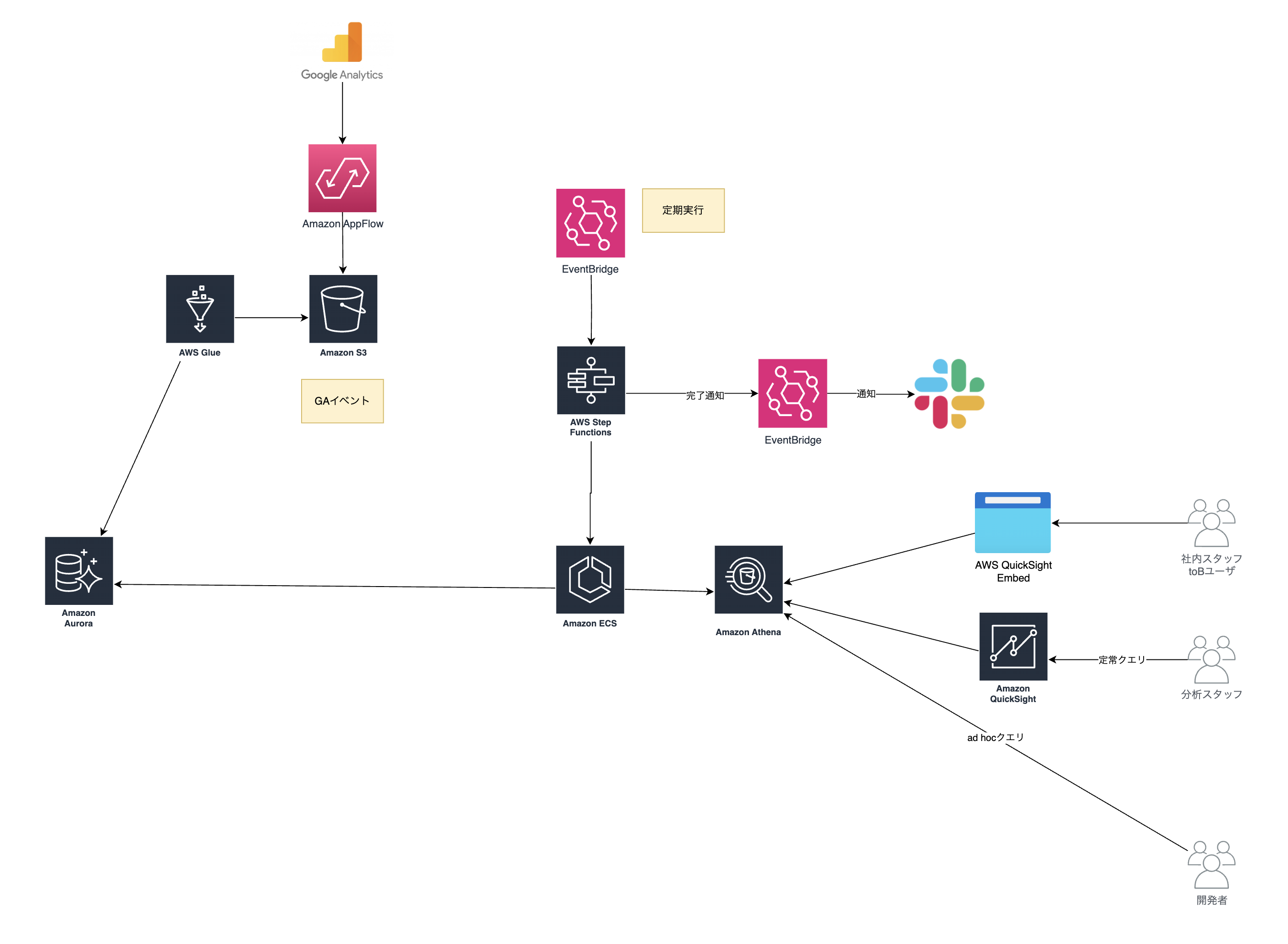
簡単に説明すると以下の機能を果たしています。
- Google AnalyticsのData APIから定期的にユーザアクセスの集計を取得してAuroraにデータを入れている。
- AuroraからPythonのコードに書いたSQLを定期的にECSで実行してAthenaから参照できるようにしている。
- QuickSightにSQLを書いてBIとして使っている。
- AthenaにアドホックなSQLを実行し分析している。
シンプルでその時に満たすべき要件を実現できていました。 ただ、コードを読み込んでみると将来的に不便になりそうな点もありました。
- AuroraからAthenaに連携するコードは、PythonにSQLを直書きしている。
- データベースに直接SQLを実行するため負荷の重いクエリだとデータベースに負担をかける。
- QuickSightにSQLが直書きされておりソースコード管理されていない。
- QuickSightでCross-source datasetsの1GB制限を超える場合がある(参考)。
- 分析用のデータセットで外部と安全に連携できる仕組みがない。
上の3つについて詳細を見ていきます。
AuroraからAthenaに連携するコードは、PythonにSQLを直書きしている
私自身も以前はSQLをソースコードに書いて、Dartで実行していました。ただ、SQLを他の言語で実行すると、以下の問題があります。
- 実行するまでSQLの構文が正しいかわからない。
- SQL同士の実行順をプログラムが制御しなければならない。SQLが多くなればなるほど大変になる。
- プログラマしかコードをいじれなくなる。データアナリストなどがコードをいじれなくなり保守性が下がる。
この課題に対しては、最終的に「dbt(data build tool)」を導入することで解決しました。 dbtを使うことで、SQLのロジックをPythonコードに直書きする必要がなくなり、SQLの管理・バージョン管理・テスト・ドキュメント化が容易になりました。
実装したときに実際に起きたのですが、データソースをBigQueryからAthenaに変えたとしても、データソースを変更し、SQLの構文を多少直すだけで適用できます。ソースコードで書いていた場合はSQL以外のコネクタなども考慮しなければならなくなります。
データベースに直接SQLを実行するため負荷の重いクエリだとデータベースに負担をかける
負荷を下げる方法として、リードオンリーのデータベースのインスタンスを用意するなど対策はあります。 ただ、テーブルが大きいと、クエリが遅かったりす負荷が高くなるのでデータ基盤用のデータウェアハウスを用意したほうがいいです。
有名どころとしては、GCのBigQueryやAWSのRedshift、Snowflakeなどがあります。BigQueryは自分の感覚としてはどんなに大きくてもほとんど1分以内でクエリが返ってくるイメージで大規模なデータも扱えます。 データベースからデータウェアハウスにエクスポートする手段としては、1日1回などのバッチ方式でやるか、CDC(Change Data Capture)でニアリアルタイム同期で行うかなどの方法があります。バッチは最新のデータが知れない、特定の時間に負荷が集中してしまうなどのデメリットがありますが、データを一括でダンプするので失敗しても再度実行すればよく、データの欠損が起きにくいです。一方で、CDCはニアリアルタイムに分析でき、コスト的にも安くなり、負荷も集中しなくなるメリットの一方で、構築難易度が高く、エラーが起きたときに原因を追求し改善したり復旧するのも面倒な事があります。CDCを選んだとしても、うまくいかなかったときのために要件によってはバッチでやることも頭に入れながら構築するといいです。
QuickSightにSQLが直書きされておりソースコード管理されていない
プログラムのソースコードにSQLが書かれていたり、QuickSightにSQLが書かれていたりしました。 まだソースコードならgit管理ができるのですが、QuickSightだと管理できません。簡単なSelectやJoinくらいならまだしも、結構ロジックが入っているものがあるとメンバが触ったときに間違えて変更されてしまうかもしれません。 簡易的以外のものはすべてソースコード管理したほうがいいと思っています。ここもdbt側に極力SQLを書けば解決です。
理想のデータ基盤設計
理想の姿を考えていきます。やっていて楽しいポイントです。理想の姿を作るとゴールに向けて邁進していけます。 (往々において理想は現実にはならないのでどこかで折り合いをつけます)
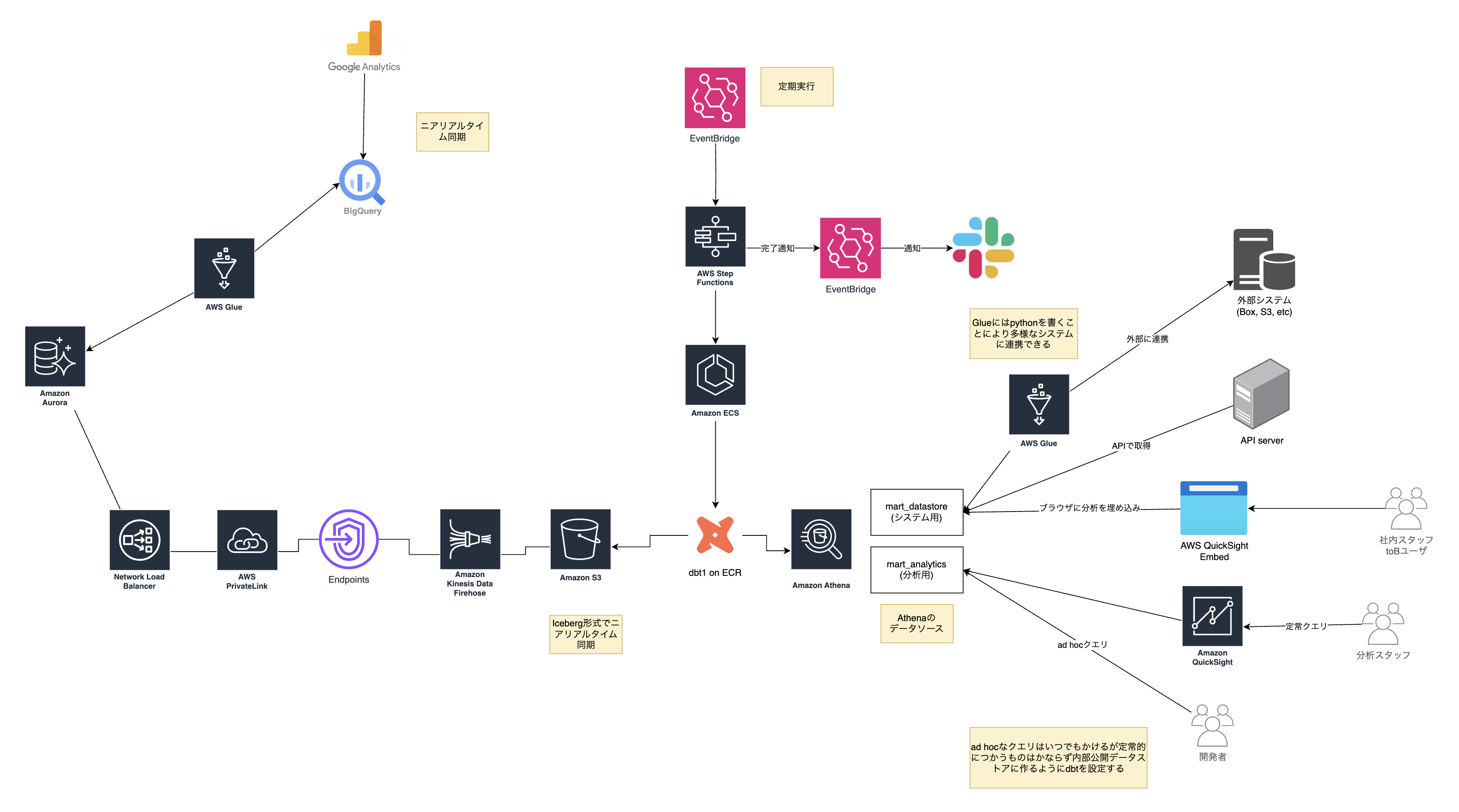
全体的にAWSを使っていたので一部を除いてAWSで統一させることを考えました。
Google Analyticsのニアリアルタイム同期
Google AnalyticsからはBigQueryにエクスポートします(参考)。ストリーミングを使えばニアリアルタイムで同期されます。理想なのですが以下の問題があります。
- ストリーミングはSLOなし。欠損していることもある。
- 代わりに1日1回エクスポートもあるが、無料の標準版だと100万件までしかイベントを出力できない。そこそこ大きな規模になると制限に容易にひっかかる。
- 1日200億件までエクスポートできる機能は1ヶ月100万以上かかり非常に高い。
今回は価格がネックで、既存のData APIを使ったバッチでの同期をそのまま使う事にしました。
Auroraのニアリアルタイム同期
AuroraをCDCでS3にニアリアルタイム同期をFirehoseで行うことができます(参考)。Debeziumを使うとDebezium自体の管理が大変だったりするのですが、AWSがマネージドで用意してくれるのは非常に楽です。しかし、この機能はまだプレビューです。GAになるまではさすがに手がだせないのでこちらも代替手段を検討しました。Auroraをマネージド環境でCDCする手段としてDatastreamを使う方法があります。エクスポート先がBigQueryになりますがマネージドなのは魅力的です。
それでは理想を見つめつつ現実どのようになったか見ていきます。
現実のデータ基盤実装
前述した通り、GAは既存の実装を残しました。
その他は順に説明します。
AuroraからBigQuery(データウェアハウス)にCDCでニアリアルタイム同期を行う
AuroraからデータウェアハウスであるBigQueryへの同期はDatastreamを使いました。設定方法はGCの公式ドキュメントを見れば比較的簡単に設定できます。 ポイントは、Auroraにどのように安全につなぎに行くのかと、同期に必要なAurora(PostgreSQL)のパラメをどのように設定するかです。 AuroraへはEC2のForward-SSH tunnelを使いました。あまりSSHの鍵を作りたくはないのですが、現状ではこの方法が一番安全なのでこちらを選択しました。
Auroraのパラメータも重要です。(参考)にもありますが、max_slot_wal_keep_sizeを正しく設定しないと同期が追いつかなくなり、同期先のテーブルを消して再同期をするという手間が発生します。ディスクのサイズや既存のデータサイズを見た上で上限なしで保存できる-1を設定しました。ただし、同期があふれていないか監視するためRDS側でslotに関するアラートを設定することをおすすめします。
Datastreamはテーブルが増えてもテーブルやカラムを指定して同期する場合と、自動で新しいテーブルも同期できる設定があります。自動で同期すると秘匿情報がはいったテーブルも同期してしまうのでプロジェクトの性質によって使い分けるといいです。
dbtでBigQueryからAthenaにエクスポートする
QuickSightからはAthenaを参照しているので、dbtを使ってBigQueryからAthenaにエクスポートします。いままでソースコードに書かれていたSQLをdbtに移植します。LLMを使いましたがPythonの中に書かれているSQLをdbt用にいい感じで書き換えてくれて大変助かりました。
図にはdbt1とdbt2が書かれています。本来1つにできるところでしたが、AthenaからBigQueryを参照するAmazon Athena Google BigQuery connectorが非常に遅く2つに処理を分ける事にしました。このコネクタは、Lambdaで動いているのですが、100万行を超えると15分以上かかってタイムアウトします。dbt1をBigQueryからBigQueryへのテーブル変換用、dbt2をBigQueryからAthenaへのデータコピー用として定義し実装しました。これでも、Lambdaの制限を超えるものがあったので、それは直接S3にPythonでエクスポートしてAthenaのテーブル定義だけをdbtに書いてしのぎました。
システム用と分析用のデータを分ける
システム用のデータとは、外部連携やWebアプリケーション内で使っているユーザや他のシステムに見える部分で容易に壊せないものです。 分析用のデータは社内用なので、それよりはいくぶん緩く使えます。
本番運用していると結構困るのがdbtでシステム用のデータと分析用のデータが同じ場所に書かれているので、分析用のSQLを変更してしまってシステム用に影響がでるというものです。そうなると分析者は安心して分析できないのできっぱり分けておくといいです。イメージとしては、セマンティックモデルみたいなSingle Source of Dataを作ってそれを分析用で利用するイメージです。
dbtはECSで動かす
dbtはdbt Cloudがあり定期実行はCloud上で設定すると楽です。ただ、dbt Cloudは、ひと月あたり1人$100かかり結構高いです。ただの実行環境のためにだけにこの費用を払うのは高いので今回はStep FunctionsとECSを組み合わせて実行しました。
その他工夫したこと
細かい工夫がいろいろあるのでここに記しておきます。
- AWSやGCのリソースは可能な限りTerraformで記述した。これにより本番・開発環境を容易に構築できた。
- GitHub Actionsでdbtのテストを行い、ビルドが通ったものだけデプロイするようにした。
- DatastreamやAuroraの監視を設定し、異常な事が起きたら通知するようにした。
- だれがどのようなSQLを実行したかは、BigQueryの場合は
INFORMATION_SCHEMA.JOBS_BY_USERにクエリをする、AWSの場合は、CloudTrailを利用した。 - BigQueryで高額なクエリが実行されないように、ユーザあたりにBigQuery APIをたたけるQuotaを設定した
- ECSは実行後1時間でログがなくなるのでロググループを作りログを保存するようにした
- 費用の見積もりは実際に動かしてみないとわからなかったので、ざっくり見積もって多くないことを確認し、新データ基盤ができあがった時点で再度確認しました。
- 新データ基盤のデータが、旧データ基盤のデータと同じかも全テーブル・全件比較しました。多少の違いがあったものの問題ない確認まで行いました。(参考)
- 外部連携用のAPIはAthenaを通して実行するようにしました。Firehoseをつかってアーキテクチャがかわっても同じように使い続けれます。
まとめと今後を見据えて
既存のデータ基盤をどのように更新したかを見ていきました。理想を定義しつつも、現実では適用できないため現実に合わせた実装をしました。ただ、理想を定義しておくことにより今後状況がかわった場合にも理想に変更することができます。今回はAWSだけにすることも容易にできるようにそれぞれを分割して作ってありDatastreamをFirehoseにしても大きく構成がかわらないようになっています。
今回は書いていないですが、ドキュメントを整えたり、監視を整えたり、エラー対応を履歴で残したり運用に役立つドキュメントも整備しました。
将来的には、メタデータ、Data Contractやロールに応じたアクセス制御の話もありますが一気にやりすぎると運用できなくなるので今回はそこは既存のままとしました。データ基盤が整った今、今後もより進化していける素地が整ったかなと思っています。