なぜスクラムをはじめたか
最近、チームの開発プロセスでスクラムを導入しました。スクラムとはなにか、なぜスクラムを導入しようとしたのか、導入してどうなったかを紹介します。
最初はこんな感じの図をつくって共有したりしていました。

TL;NR
- 現状のチーム開発では「ドメイン知識の伝搬不足」「客観的な見積もりができない」「仕様理解の不足」という課題があった
- 改善するためにスクラムを徐々に導入した
- まだ課題はあるもののいい感じにすすんでいる
スクラム導入前のチームの開発状況
開発でスクラムが導入されていなかったということは、その時点ではスクラムをしなくても開発がまわっていました。
当時の開発は以下のようになっていました。
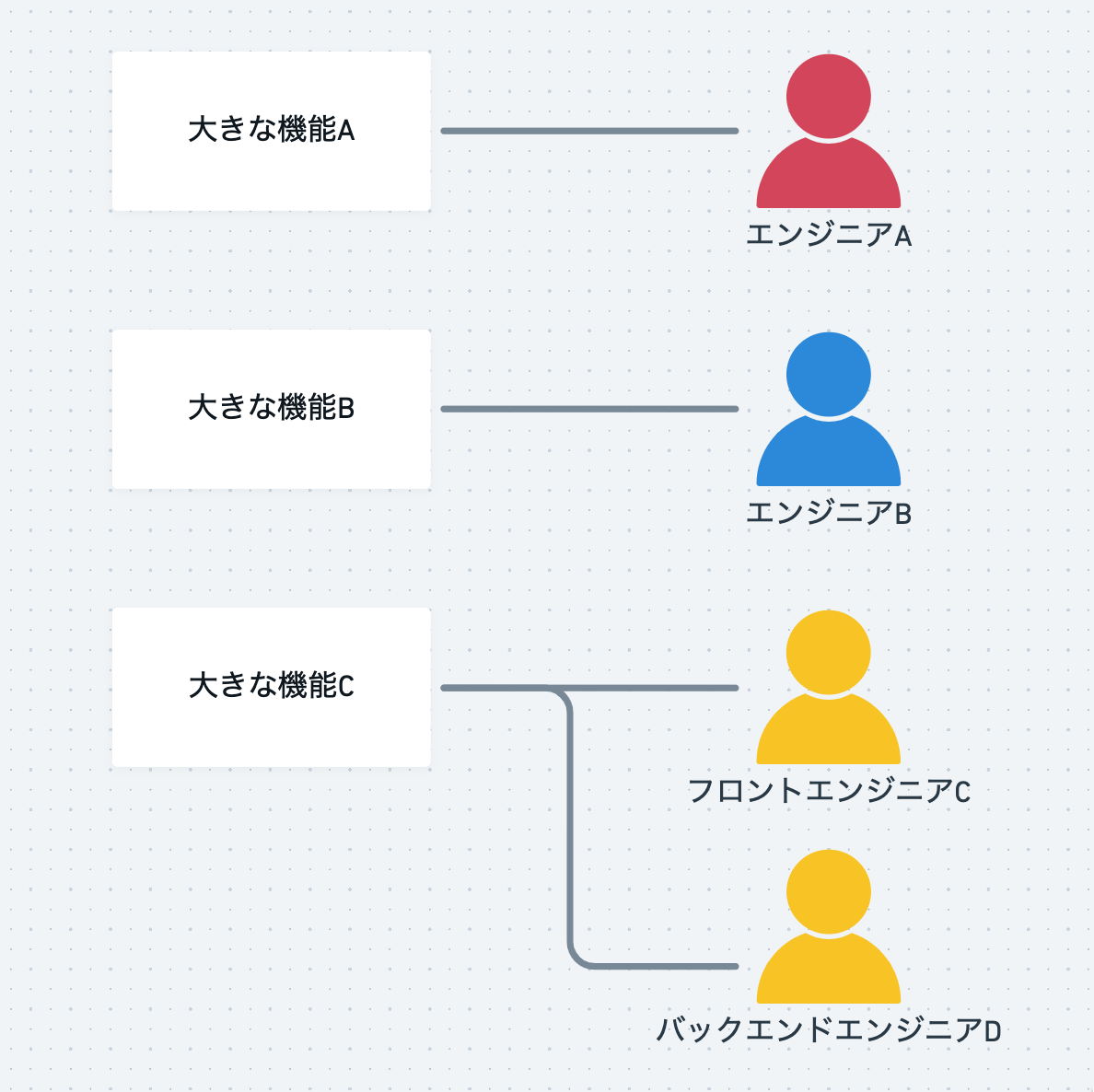
とある機能が大きかろうが小さかろうが基本的に開発は1人が担当します。時々相当大きいときはフロントとバックエンドに分かれて2人で開発したりしましたが担当が固定され開発されていました。実装がおわるとコードレビューされリリースされます。なんとなく1週間がスプリントと呼ばれる開発単位になっていましたが最初にタスクの進捗を確認するみたいな役割しかもっていなかったです。
しばらくはよかったのですが以下の課題が出てきました。
- ドメイン知識の伝搬不足: 機能をごく少ない少人数で担当するため開発は早いがその機能のドメイン知識がその機能を開発したメンバのみにしか行き渡らない
- 客観的な見積もりができない: 大きな機能単位で開発しているのでおおざっぱな見積もりしかできない。また見積もり単位がエンジニアによるので他のエンジニアが担当したときにスケジュールがずれる
- 仕様理解の不足: 機能開発を少人数の視点で担当しているので仕様の見逃しがあり後工程で開発する機能が増え見積もりが増える
多くの開発する機能が出てきており、開発する人数が増える中で上記の状態で開発を続けるのは、開発全体のスループットがリニアにスケールしない状況であり問題との認識がありました。
スクラムとは
スクラムに関して知識を得たい場合は以下のガイドが役立ちます。
Jira、Confluence、スクラム フレームワークの使用を開始する | Atlassian
上記をまとめたのが以下になります。あくまでざっくり概要を掴むものだと思っていただければと思います。
スプリント中のイベント
すべての基本となるものがプロダクトバックログです。バックログとはすべてのタスク(GitHubやJIRAだといわゆるIssueと呼ばれているもの)が優先順位順にならんでいるものです。
そのタスクをチームで決めた単位(1週間とかX週間)のスプリントと呼ばれる期間でチームで実行できる単位のタスクにまとめる作業をプラニングとよびます。プラニングをするとスプリントで実行するスプリントバックログができます。
スプリント中は日々の進捗確認やブロッカーの確認をするためにデイリースクラム、いわゆる朝会をやります。
スプリントの最終日にスプリントが終わる前にスプリントレビューと**レトロスペクティブ(振り返り)**を行います。スプリントレビューは成果物のデモを行います。デモを行うことにより実際に動く形でプロダクトが見えたり機能開発お疲れ様とねぎらうことができます。振り返りではKPT(Keep/Problem/Try)などで今後の改善を話し合います。ただ話し合うだけではなく改善点をプロダクトバックログに積みます。これによりただ振り返って終わりではなく改善が実際に導入されることになります。この振り返りは特に重要でチームの開発プロセスの継続的な改善に繋がります。
スプリント前のイベント
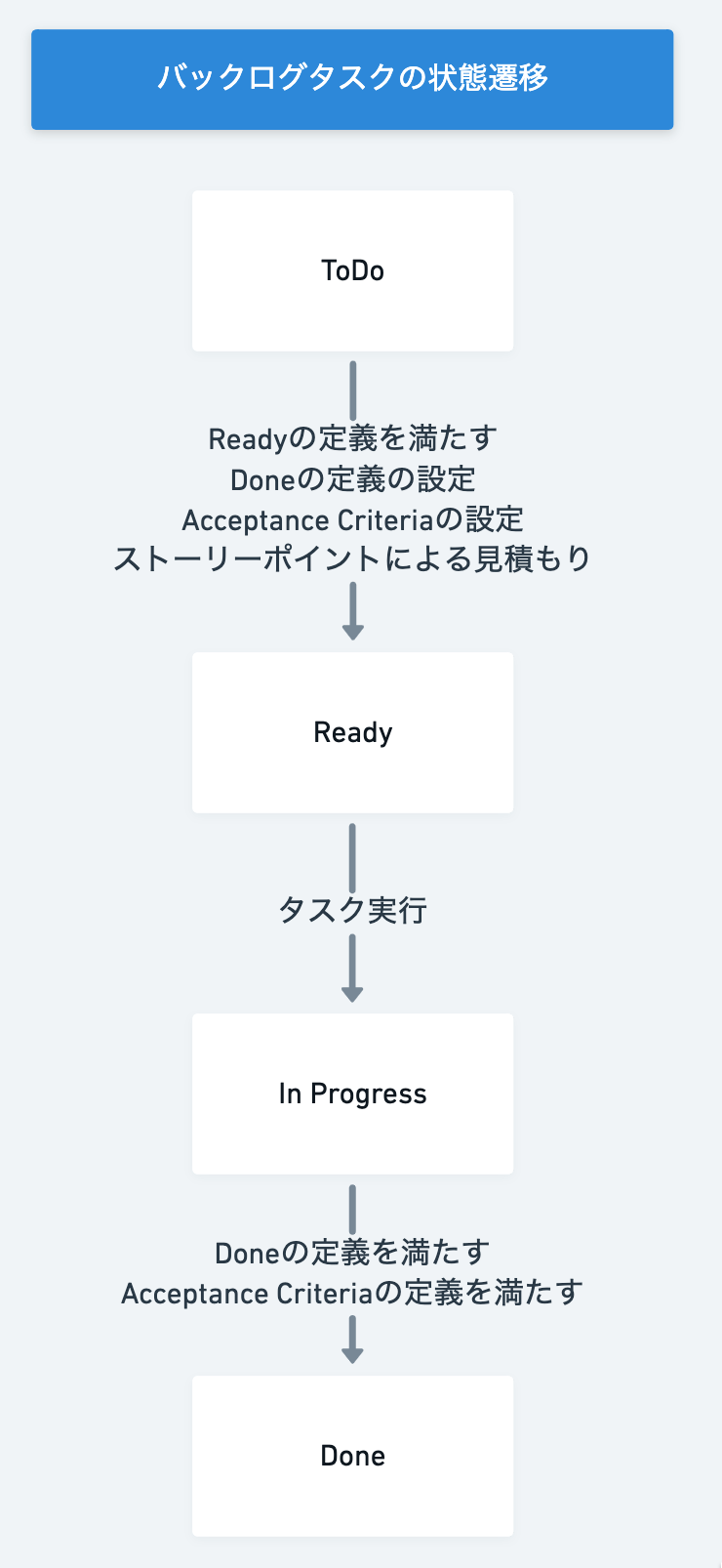
スプリント前にスプリント中に実行するであろうバックログのタスクが開発に取り書かれるように準備する作業をリファインメイントといいます。バックログはタイトルさえ書いてあれば実行できるだろうと思いますがそうではありません。もちろん不具合など見ればすぐわかるものもありますが機能などは仕様書も必要だしデザインも必要だしと取り掛かる前に準備すべきことがあります。そのようなバックログのタスクを実行する前に必要なことを”Definition of Ready(Readyの定義)”と言います。
さらにタスクには完了にするまえに満たすべき条件があります。例えばユニットテストが書いてあるなどです。そのような条件を”Definition of Done(Done の定義)”と呼びます。またリリースされるまえにQAを行う、パフォーマンスが一定の条件を満たしているなどの”Acceptance Criteria(受け入れ条件)”も定義する場合もあります。
その上でタスクの見積もりを行います。この見積もりは相対見積もりでそのポイントをストーリーポイントと呼んだりします。どれか1つのタスクの工数をXストーリーポイントと定義し、そのストーリーポイントと比較してどのくらいのポイントかを各タスクに振っていきます。スプリントでどれだけのタスクの合計ストーリーポイントを実行できたかでチームのベロシティ(開発のスピード)がわかります。これを使うと、長期的にタスクのストーリーポイントを合計しチームのベロシティ(例えば直近3週間の平均などとします)でで割るとどのくらいの期間が開発にかかるかざっくりわかります。ただこのベロシティは様々な理由でかわるのであくまで目安です。
まとめると以下です。この定義をしっかりしておかないとタスク実行者にはタスクが終わりになっているがPM的にはまだ隠れた条件を満たしていないのでおわっていないとなってしまうのでリファインメントでしっかりと定義しておく必要があります。
どのようにスクラムが導入されたか
当時は導入した経緯はスケジュールを精緻化させたいという目的でした。半年ほどのスケジュールの期間でタスクを見積もりをし、その見積もりを使って機能を取捨選択しスケジュールにあわせていくという事を達成するためにストーリーポイントにより見積もりを導入しました。その当時はGitHub Project Betaのカスタムフィールドを使ってストーリーポイントを導入しスプリントに分けて開発していました。
長期的なスケジュール上でスプリントに分け、ストーリーポイントを入れだすと、GitHub Project Betaでは対応できなくなりました。そこらへんは以下に経緯をかきました。
なぜプロダクト開発のツールとしてNotionとGitHubでは不十分なのか | wapa5pow's blog
スクラムツールとしてJIRAを導入し徐々に「スクラムとは」で説明したプロセスが導入されていきました。ひとまずイベントをやってみるとそのイベントに必要な人数ややることへの解像度がどんどんあがっていきます。最初は必要そうでないメンバもよんでしまい時間をとってしまったこともあるのですが、ひとまずやってみてどんどん振り返りで改善できたのがよかったかなと思っています。
その他、大きな機能をまずチームで共有しそれを分割されたタスクにし、それぞれを見積もってチームで分担できるようになりました。これによりドメイン知識が一部のメンバだけでなくチーム全体として共有できタスクを安定して実行できるようになったと感じています。
スクラム導入時の注意
スクラムはガイドがあるもののかちっと決まっているわけではなく、個人的にはチームや状況に合わせて柔軟に合わせていくのがいいかなと思っています。最初からかちっと導入するとチームへの負荷が高まり納得しない状態ですすむことになります。まず必要だと思っているところからそして徐々にスクラムへの解像度が高まった段階でどんどん改善していくのがいいと思っています。そのために振り返りがあるのですから。
今後の改善ポイント
まだまだ導入したてで小さなチームでやっている状況なのでこれからもどんどん改善していけると思っています。とくに以下の点かなと思っています。
- Definition of Ready, Definition of Done, Acceptance Criteriaをしっかり定義し各タスクで設定し満たすようにする
- QAや他のチームでもプロセスを広めていき役立ちそうなら採用してもらう
- このプロセスの採用がすすむと全体のスケジュールの見通しも立てやすくなるし一覧でみれるようになる
- 1つのスクラムチームではなく複数のスクラムチームでもちゃんとまわるようにする
プロセスを定義するのはかちっとしてあまり好きではなかったりするのですが、人数が増えても、雑事にとらわれず集中できる環境をつくり、やるべきことをやり、それがプロダクトの進捗につながるのが本質的な改善ではないかと思っています。