GKEを使っているときの非同期処理の実現方法と設定
Webアプリケーションを開発していると非同期で処理したいことがあります。
たとえば、注文が終わったあとにメールを送りたいという場合です。注文時にメール送信の処理をするとメール処理の時間が長いのでレスポンスが遅くなってしまいます。これを防ぐためにメール処理は非同期に行うことがあります。
非同期処理を実現する1つの方法としてPubSubにメッセージをPublishし、Workerをつかいメッセージをサブスクライブしてメール送信を行います。
もう一つの方法としてCronでバッチ処理をし注文はされているがメール送信されていないものを抽出しメール送信を行います。
今回は、GKE(Google Kubernetes Engine)でWorker、Cronの実現方法と設定について説明します。WorkerとCronの概念はわかるけれどもGKEではどう実現すればいいか知りたい場合に役立つように書いていこうと思います。
WorkerとCronの使い分け
| Type | 実現方法 | 使い分け | | ---- | ---- | ---- | | Worker | Deployment | 処理をすぐ行いたい・処理時間が短い | | Cron | CronJob | 定期的に実行したい・処理時間が長くてもよい |
簡単に分類すると上記のようになります。WorkerとCronについ順に説明します。
Worker
GKEでWorkerはDeploymentとして実現します。Deploymentはアプリケーションのサーバを動かす時にも使っているものでWorkerも同じように常駐させます。
Cloud Pub/Subは以下のような構成になっています。Worker=Subscriberです。
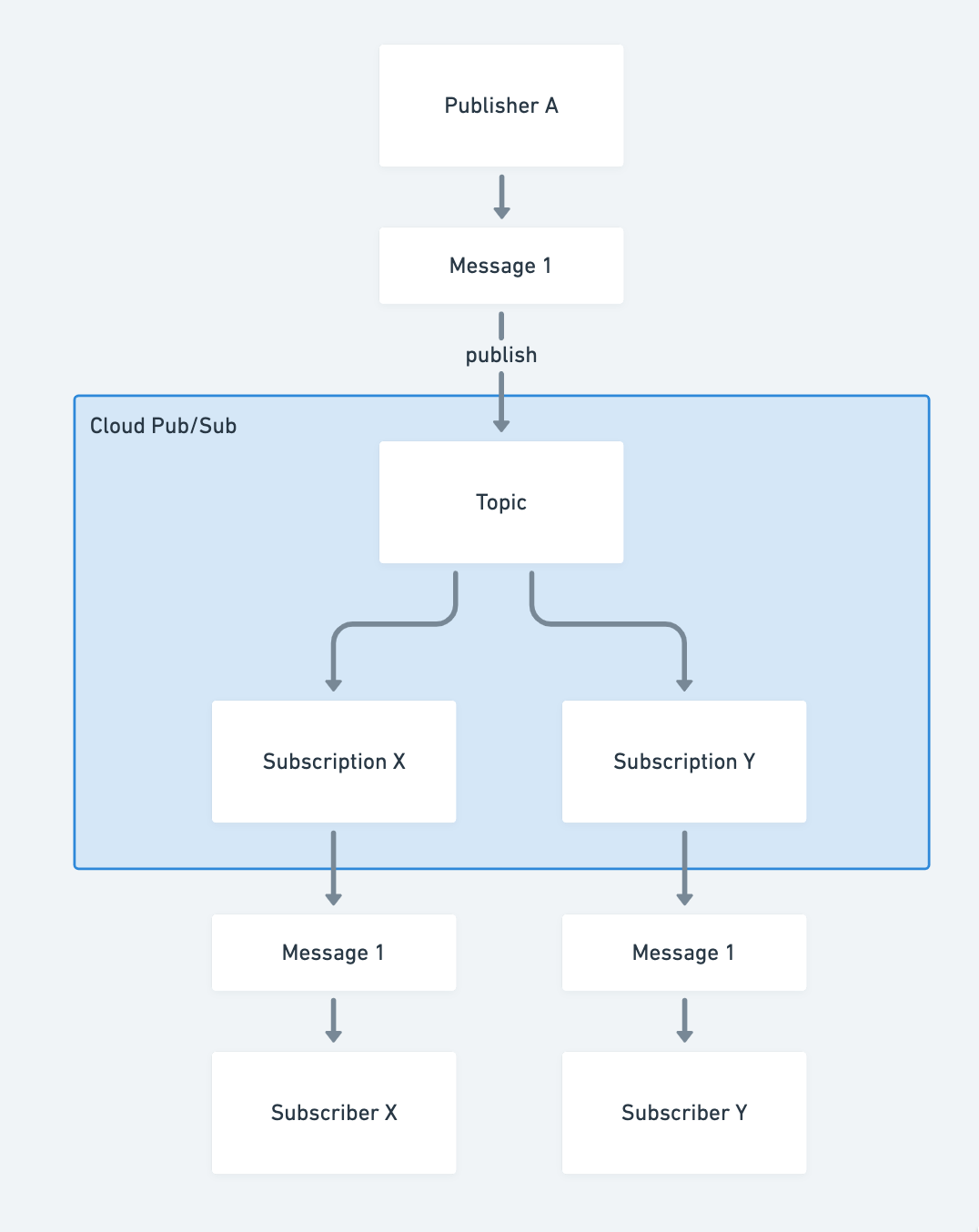
Publisher AがMessage 1をTopicに送ります。Topicは、紐付けられているSubscriptionすべてにMessage 1を送ります。 Subscriber XはMessage 1が来たら順次処理をします。処理が終わったらAckを返すとMessage 1は処理されたということになります。
Subscriptionには確認応答の期限(Acknowledgement deadline)が設定でき、Ackを返さないでその時間が経過すると再配信処理を行います。 再配信処理は即時の再配信(Retry immediately)と指数バックオフ(Retry after exponential backoff delay)があります。筆者は即時の再配信を使うことが多いです。
実行時の安定性の向上
メッセージの確認応答の期限
確認応答の期限は最大10分なのですが、延長することができます。つまり10分の期限を設定しておき、9分ほどたったら再度10分に設定でき期限を伸ばすことができます。 このようにすることでWorkerでも10分以上の長時間かかる処理ができます。 ただし、筆者はあまりWorkerで長い処理はさせないように意識しています。Worker自体はDeploymentなので縮退してPodがなくなってしまって途中で処理がおわってしまう場合があるからです。 その場合でも途中経過を記録して、その時点から再開させればいいという話ですがその実装自体が面倒だと思うので処理自体を短くして縮退しても大丈夫ないようにします。
最低1回(at-least-once)か1回限り(exactly once)の配信か
デフォルトでは、Pub/Subは最低1回配信されます。逆に言うと同じメッセージが何回か配信される可能性があるということです。 よってWorkerでは同時にメッセージが来ても大丈夫なようにロックしたり、何度きても同じ処理になるように冪等性をもたせたりする必要があります。
1回限り(exactly once)というオプションもあります。ドキュメントによると通常のサブスクリプションよりレイテンシが大幅に大きくなるようです。
エラー対応
メッセージの保持期間
Subscriptionでメッセージが処理されずに残っていたときにそのメッセージをどのくらいまで保持しておくかが保存期限(Message retention duration)です。 最大7日なので、処理できなくて失敗したメッセージや処理能力を超えてしまって残ったメッセージは、この期限が切れる前に処理します。もし処理できなければ消えてしまいます。
Cloud Pub/Subには処理されずに残っているメッセージがどのくらい時間がたっているかのメトリックスがあるので一定時間滞留しているメッセージがあればアラートを出す処理をして検知します。
失敗したメッセージの扱い
前述したように、メッセージの保持期限まで同じサブスクリプションで保持しておく方法と、別のサブスクリプションに、一定回数試して(配信試行回数)失敗し続けたしたメッセージを送り、サブスクリプションからは消す、デッドレタートピックという方法があります。 配信試行回数は5~100回を設定できます。
筆者の使い方だと、失敗しているものはデッドレタートピックに送っておき、メッセージの中身をWebコンソールで確認します。すぐ直せそうならば修正してデプロイし、デッドレタートピックのサブスクリプションから再度元のメッセージにPublishしなおして処理をしてもらいます。以下のイメージです。
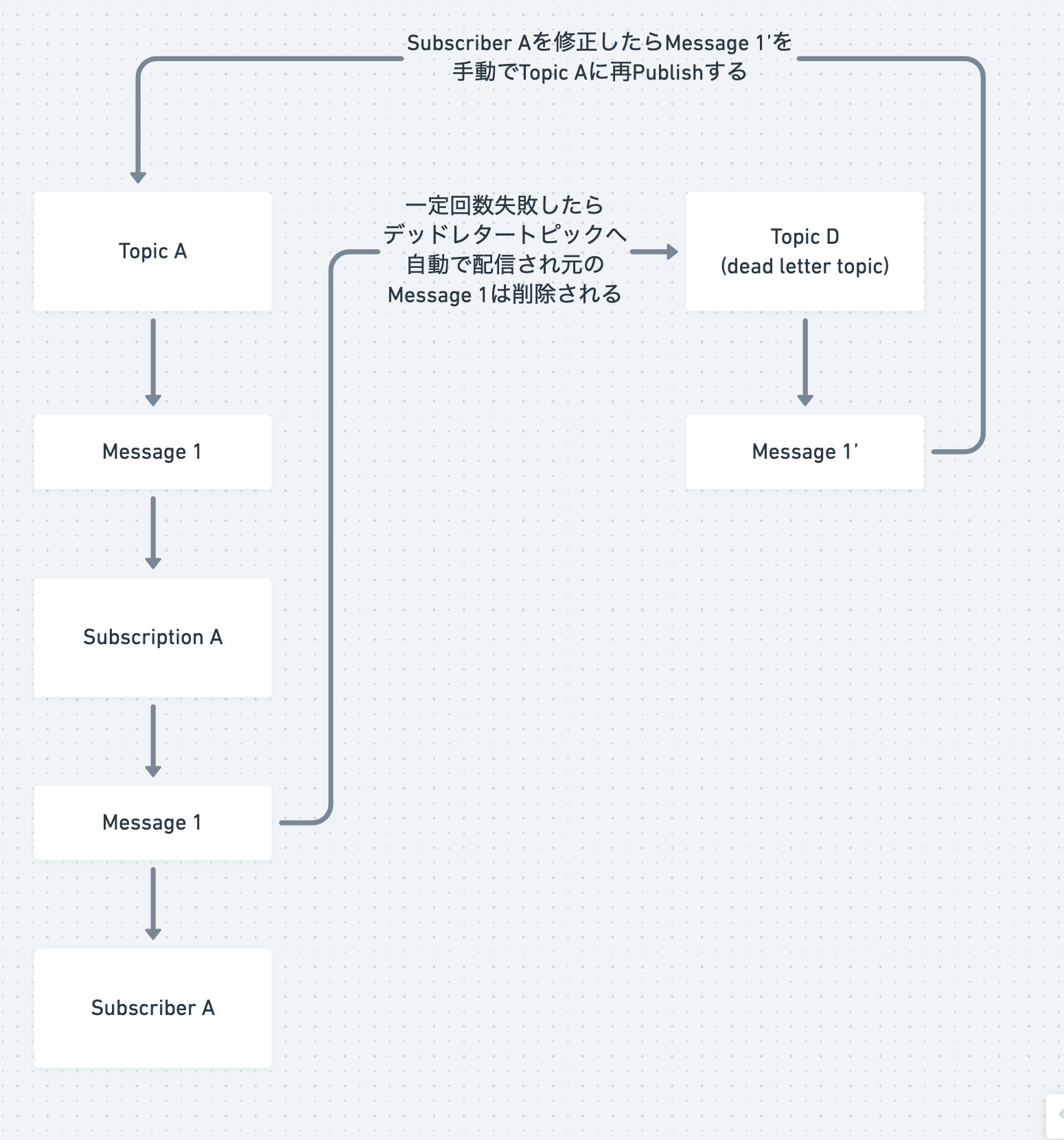
デッドレタートピックに送りたい理由は、失敗したメッセージが一定時間滞留すると、アラートがなり続けるのでいったん退避させたいのとWebコンソールで失敗しているメッセージだけみたいという理由です。
スケールとレート制御
Workerが更に外部にリクエストするときに並列度を調節したいときがあります。例えば、外部のサイトをクローリングしていてクロールの並列度を最大10としたい場合です。 そのようなときはWorkerを最大10 Podのみ起動できるようにHorizontal Pod Autoscalingを設定し最大10 Podしか起動しないようにします。
監視
以下の2つを主に監視します。
- Oldest unacked message: 処理されていないメッセージがどのくらの時間サブスクリプションに滞留しているか。エラーがあり処理されなかったり、処理能力が足りなかったりすると滞留する。
- Unacked messages by region: どのくらいAckを送られていないメッセージが滞留しているか。
以下がメトリックスの例です。運用時にメトリックスをみて適切な値を設定するといいと思います。

その他は状況に応じて設定してください。
その他の実現方法
GKEでと最初限定しましたが、Cloud Runなどを使えるのならばWorkerはCloud RunでPub/Subを使用するで実現することができます。 Deploymentにすると常に起動しておかなければなりませんがCloud Runならばメッセージがあるときだけ起動できお財布にもやさしいです。 ただ、まったく起動していない場合は、起動時間が数秒程度かかることがあるのでできるだけ素早く処理をしたいときは常に起動しておく必要があります。 こちらも設定でオートスケールできます。
Cron
GKEではCronJobを設定するとCronを動かす事ができます。 ドキュメントに書かれているのですがいつも設定する項目があるので説明します。
実行時の安定性の向上
Evictされないようにする
GKEで状況によってはCronJobのPodが縮退してしまうことがあるので.spec.jobTemplate.spec.template.metadata.annotationにcluster-autoscaler.kubernetes.io/safe-to-evict: "false"を設定しておきます。長時間かかる処理が途中でとまって再度再開されると最初処理に時間がかかってしまいます。
縮退しても大丈夫にするようにはCronにも冪等性と途中から再開できるような機構を入れる必要があります。
同時実行制御
1分毎に動作しているCronがあったとして処理が1分以内に終わらなかった場合次のCronを動かすかどうかの設定です。.spec.concurrencyPolicyに、Allow、Forbid、Replaceのいずれかを設定できます。
たいてい筆者はForbidにして前のJobが終わるまで待っています。
エラー対応
最大実行時間を設定する
処理がなんらかの理由で止まっているときなどのために強制的に処理を終了させたいことがあります。
そのための最大時間を設定するには、Jobの.spec.activeDeadlineSecondsを設定します。
失敗したら再試行する
時々失敗する場合はJobの.spec.backoffLimitを設定して再試行回数を設定しておきます。
スケールとレート制御
処理対象が多い時など特定の時間に複数Cronを起動したいときがあります。たとえば0時に前日の締め処理を行うような場合です。並列で動かしたいときはJobの.spec.parallelismと.spec.completionsを設定します。
またKubernetesの1.24からIndexed Jobが使えるようになっています。
よって以下のように設定すればCronJobで3並列でJobが動かせることができ、それぞれJOB_COMPLETION_INDEXの環境変数に0, 1, 2と入って実行できます。3並列で3つが終わるとCronが完了となります。
apiVersion: batch/v1
kind: CronJob
metadata:
name: indexed-job-cron
spec:
schedule: "* * * * *"
jobTemplate:
spec:
completions: 3
parallelism: 3
completionMode: Indexed
template:
spec:
containers:
- name: indexed-job-cron
image: busybox:1.28
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- echo JOB_COMPLETION_INDEX=$JOB_COMPLETION_INDEX
restartPolicy: OnFailure
監視
CronJobの監視は結構面倒です。以下で監視について述べましたがいまだ自分の中でベストプラクティスが定まっていません。最近はTypeScriptでkubectl get pod -A -o jsonの結果を読み込んでログを出すみたいなことをしましたがやはり面倒です。。。
まとめ
GKEでWorkerとCronをどう扱うかを解説しました。様々なオプションがあるので各種理解しつつ安全にアプリケーションを開発できるといいですね。