新規でWEBサービスを作るなら採用するデータ連携を考慮したアーキテクチャ
前回の記事「書籍「大規模データ管理」を読んで考える、開発者もデータ利用者も幸せなアーキテクチャ」でアーキテクチャを考えてみました。
前回は概念でしたが今回は、自分が新規でWEBサービスを作るならこのようなアーキテクチャを採用するというのを紹介しようと思います。
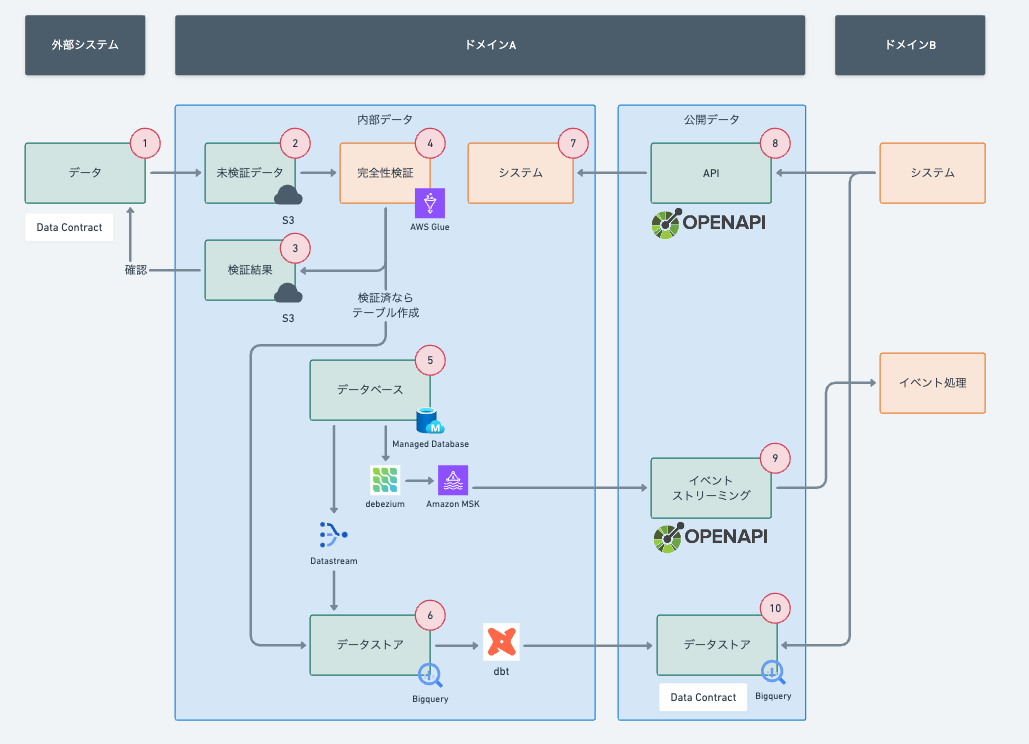
アーキテクチャで以下を意識しました。
- データストアはニアリアルタイムでデータベースから同期する: リアルタイム分析のニーズが高まっているのでデータベースから1日1回エクスポートという形ではなくニアリアルタイムでスケーラブルに分析できるようにする
- サービスは可能な限りマネージドのものを使う: データベースやKafkaなどのサービスは運用が大変なので開発に集中するためなるべくマネージドのものを使います。
- 公開データの定義は言語によらない記述とする: OpenAPI, Data ContractはYAMLで記述してあります。YAMLをTypeScriptなど複数の言語にコンバートできるためクライアントの言語が制限されません。
実際にどのように実装するか説明します。コード生成はTypeScriptを前提としますが他の言語でもGeneratorさえあれば生成できます。
1の外部連携データの定義をData Contractで行う
外部連携ファイルは、どのようなフィールドをもっていてどのような制約があるのか確認することが大事です。それらをドキュメントにして外部連携元のパートナーと合意する必要があります。
Data ContractはCSVやJSONなど各種データの定義や制約をYAMLやJSONで記載することができます。OpenAPIのデータ版だと思えばいいと思います。
例えば以下のようにData Contractを定義することにより、ファイルのフィールド名や各フィールドの制約を定義できます。 細かい検証はSodaCLを使っても検証できます。
dataContractSpecification: 0.9.3
id: datastream_sample
info:
...
servers:
production:
type: s3
location: s3://...
format: csv
models:
todos:
description: All of Todos"
type: table
fields:
id:
type: long
description: "ID"
nullable: false
primaryKey: true
title:
type: string
description: "Title"
minLength: 1
maxLength: 100
completed:
type: boolean
description: "Completed"
nullable: true
description:
type: string
description: "Description"
nullable: true
quality:
type: SodaCL
specification:
checks for todos:
- row_count > 1
- duplicate_count(id) = 0
定義からData Contract CLIを使ってドキュメントを作成できます。このHTMLをパートナーと合意することにより不正なデータが来たときに制約条件をみたせていないことを主張できます。
datacontract export --format html datacontract-s3.yaml > datacontract-s3.html
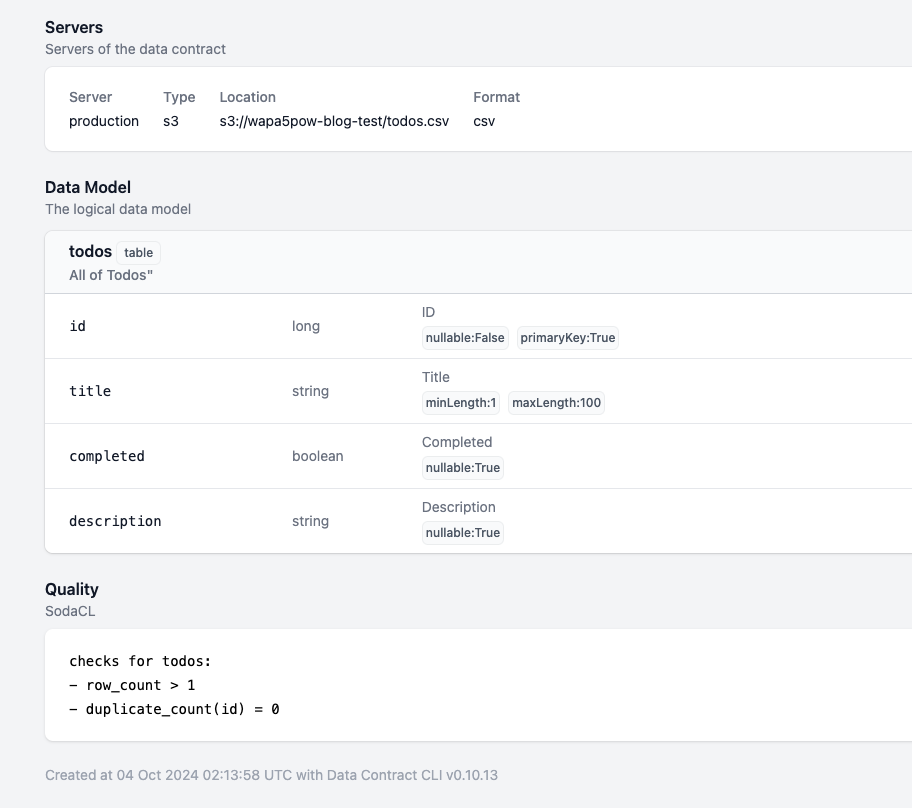
ドキュメントや制約を検証することもできます。
$ datacontract test datacontract-s3.yaml
Testing datacontract-s3.yaml
╭────────┬────────────────────────────────────────────────┬───────┬─────────╮
│ Result │ Check │ Field │ Details │
├────────┼────────────────────────────────────────────────┼───────┼─────────┤
│ passed │ Check that field id is present │ │ │
│ passed │ Check that field title is present │ │ │
│ passed │ Check that field completed is present │ │ │
│ passed │ Check that field description is present │ │ │
│ passed │ row_count > 1 │ │ │
│ passed │ Check that field title has a min length of 1 │ title │ │
│ passed │ Check that field title has a max length of 100 │ title │ │
│ passed │ duplicate_count(id) = 0 │ id │ │
╰────────┴────────────────────────────────────────────────┴───────┴─────────╯
🟢 data contract is valid. Run 8 checks. Took 1.120317 seconds.
Data Contract CLIでいろいろできそうなのですが動作検証していくなかでエラーが見づらいとか、CSVの形式によってはエラーがでたりと若干不安なところがあります。 定義を開発者ではなくても書けたり、HTMLで共有できるところはいいのですがまだ発展途上な感じがします。 よって、後述のプロダクト内部に取り込むときにはAWS Glueで検証しBigQueryに同期しています。
2の外部連携から来た未検証のデータを検証する
外部連携から取得するデータは、ドメインの内部に入る前に完全性を検証します。
AWS Glueのデータ品質定義言語(DQDL)で外部連携で送信されるファイルを連携元が自律的に検証できるようにするで方法を紹介したの参考にしてください。
3の検証結果に保存し、パートナーが自律的に正しいファイルをおいたか確認できます。検証後、6のデータストアに配置しドメイン内で使えるようにします。
5のデータベースから6のデータストアへDatastreamで連携
データベースはマネージドのデータベースを使います。
アプリケーション処理や分析時にデータベースをクエリしたいという要求が起こります。無秩序にデータベースにクエリされるとパフォーマンスの問題があるので、データストアに同期します。昔は1日1回など同期していたのですが最近はリアルタイムで分析したいという要求もよくあります。よってニアリアルタイム(数分もの遅延なく)同期する方法を考えます。
データベースからデータストアにはDatastreamでニアリアルタイムでデータベースのテーブルの変更をそのままBigQueryに送ります。Datastream を使用して準リアルタイムにデータを BigQuery にレプリケートするを参考にして実装します。
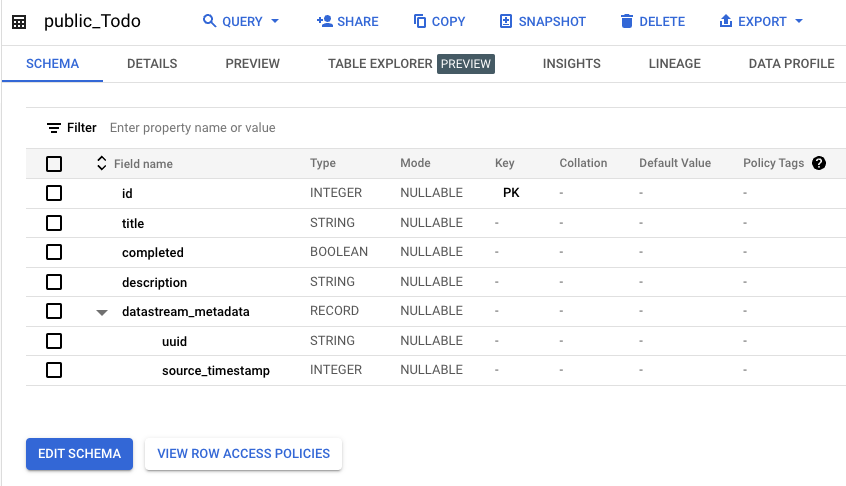
新しいテーブルが作られても自動でBigQueryにテーブルが作られるので手間なくデータストアを作成・利用できます。
同期されると元のテーブルデータにdatastream_metadataが付与されたBigQueryのテーブルが作成されます。
5のデータベースから9のイベントストリーミングへのdebeziumとAmazon MSKを使った連携
別ドメインへイベントを通知しそれに応じて処理をさせたいときがあります。データベースに書き込んだ後にイベントを処理するサービスに送ってもいいのですが、処理が失敗したときなどデータベースの整合性を取るのが面倒です。 Outboxパターンを利用し、データベースに書き込んだものをイベントとして送るようにします。
データベースの変更はdebeziumで検知してKafka(Amazon MSK)に送って7のイベントストリーミングとして使用します。
debeziumはテーブル名などでフィルタできるのでテーブル名のサフィックスがEventのものだけ送るということもできます。
Amazon MSK デベロッパーガイドやDebezium ソースコネクタ (設定プロバイダー付き)を参考に実装します。
debeziumは何も設定しないとレコードが追加されたら以下のようにKafkaにメッセージが来てJSONのネストが深いです。(参考)
{
"schema": // ...,
"payload": {
"before": null,
"after": // モデルの中身,
}
}
debeziumで以下のように設定するとpayload以下のメッセージにすることができます。
{
"name": "postgres-connector",
"config": {
...
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false
}
}
通常だと追加・更新・削除すべてのイベントが流れてくるのですが、フィルタして追加だけにしたり、after以下のみメッセージするなどもできるようです。
外のドメインから見ると、9のイベントストリーミング(Kafka)でどのトピックに、どのようなデータが流れてくるか気になるところです。 イベントを定義するためにOpenAPIを使います。 (当初、AsyncAPIを使おうと思ったのですが、コンバーターがいまいちだったのでOpenAPIを使います)
openapi: 3.0.0
info:
title: Todo Service
version: 1.0.0
description: A service for managing todo items
paths: {}
components:
schemas:
CreateTodoEvent:
description: |
Topic: postgres.public.CreateTodoEvent
Todoが作成されたら作成されるイベント
type: object
required:
- hash
- todo_id
- title
- description
properties:
hash:
type: string
format: uuid
description: Unique identifier for the todo item
todo_id:
type: integer
format: int64
description: Unique identifier for the todo item
title:
type: string
description: Title of the todo item
description:
type: string
description: Detailed description of the todo item
descriptionにTopicの情報など書くといいでしょう。これをTypeScript用にコンバートします。
npx openapi-zod-client openapi-event.yaml -o src/event/event.ts --export-schemas
以下のようにワーカーを書くとKafkaから処理できます。
import { Kafka } from "kafkajs";
import { z } from "zod";
import { schemas } from "./event/event";
const kafka = new Kafka({
clientId: "todo-event-consumer",
brokers: ["localhost:9092"],
});
const consumer = kafka.consumer({ groupId: "todo-event-group" });
interface EventEnvelope<T> {
before?: T;
after?: T;
}
const EventEnvelopeSchema = <T extends z.ZodTypeAny>(schema: T) =>
z.object({
before: schema.nullable().optional(),
after: schema.nullable().optional(),
});
const parseEventEnvelope = <T extends z.ZodTypeAny>(
value: string,
schema: T
): EventEnvelope<z.infer<T>> => {
const parsed = JSON.parse(value);
return EventEnvelopeSchema(schema).parse(parsed);
};
// 以下のコードを追加
const run = async () => {
await consumer.connect();
await consumer.subscribe({
topic: "postgres.public.CreateTodoEvent",
fromBeginning: true,
});
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
try {
const createTodoEvent = parseEventEnvelope(
message.value?.toString() || "{}",
schemas.CreateTodoEvent
);
console.log({
hash: createTodoEvent.after?.hash,
todo_id: createTodoEvent.after?.todo_id,
title: createTodoEvent.after?.title,
description: createTodoEvent.after?.description,
});
} catch (error) {
console.error("メッセージのパースに失敗しました:", error);
}
},
});
};
run().catch(console.error);
6のデータストアから10のデータストアへの連携
別ドメインから分析などで使ってもらうため10のデータストアを用意します。 使う側はどのようなテーブルがあるのか知りたいので、Data Contractを定めます。そのData Contractに沿ったデータをdbtで作成します。
dbtは資料が豊富なので各種WEB上を参考にして実装します。
Data Contract CLIでdbtのモデルやソースもエクスポートすることができます。 例えば以下のようにBigQueryのテーブルを定義します。
dataContractSpecification: 0.9.3
...
servers:
production:
type: bigquery
...
models:
public_Todo:
description: All of Todos"
type: table
servicelevels:
freshness:
interval: 1d
freshness: 1d
fields:
id:
type: long
description: "ID"
nullable: false
primaryKey: true
title:
type: string
description: "Title"
minLength: 1
maxLength: 100
completed:
type: boolean
description: "Completed"
nullable: true
description:
type: string
description: "Description"
nullable: true
10のデータストアのために作成するdbtのモデルを以下で生成できます。
datacontract export --format dbt datacontract.yaml > dbt/models/schema.yaml
さらに別ドメインが使うときはソースとして以下で生成できます。
datacontract export --format dbt-sources datacontract.yaml > dbt/models/sources.yaml
Data Contractによりdbtのソースやモデルのコードが自動で生成できました。
8のAPIでOpenAPIの定義からTypeScriptのコードを生成する
APIはドメイン外からドメイン内のデータを更新したり参照するために提供します。 OpenAPI定義から以下の2つのコードを生成できる必要があります。
- APIとして公開するためのサーバ用のコード
- 公開されたAPIにアクセスするためのクライアント用のコード
サーバ用のコードは以下のように生成します。
npx swagger-typescript-api -p openapi.yaml -o src/server --no-client --route-types --extract-response-error --type-prefix Api -n openapi.ts --responses
クライアント用のコードは以下のように生成します。クライアントはzodを使っているのでフォームのエラーメッセージも楽々です。
npx openapi-zod-client ./openapi.yaml -o ./src/client/client.ts"
まとめ
次に新規プロダクトを作るときのアーキテクチャを妄想してみました。 普段の開発を離れ、理想ベースで何ができるか考えるとそれに向かって既存のプロダクトの改善も見えそうです。